一个简单的示例:网页元素
1、前言
在上文 一个简单的示例:基础知识 中,我们完成了一个非常简单的Demo:
- 在花漾浏览器中新开一个标签页
- 在新开的标签页中访问 baidu.com
本文我们将对上述示例进行扩充,增加以下内容:
- 在百度首页中定位到Search框,并输入检索词
- 按回车进行检索
通过本文的阅读,您将了解:
- 什么是网页元素
- 如何通过花漾灵动“元素捕获器”对网页元素进行定位
2、关于网页元素
本章节我们要谈及一个非常重要的概念:网页元素。为了方便您的理解,我们给您准备了一个非常简单的网页 demo.html, 其源码为 demo.html的源码 ,下图是用浏览器访问此网页的展示效果:
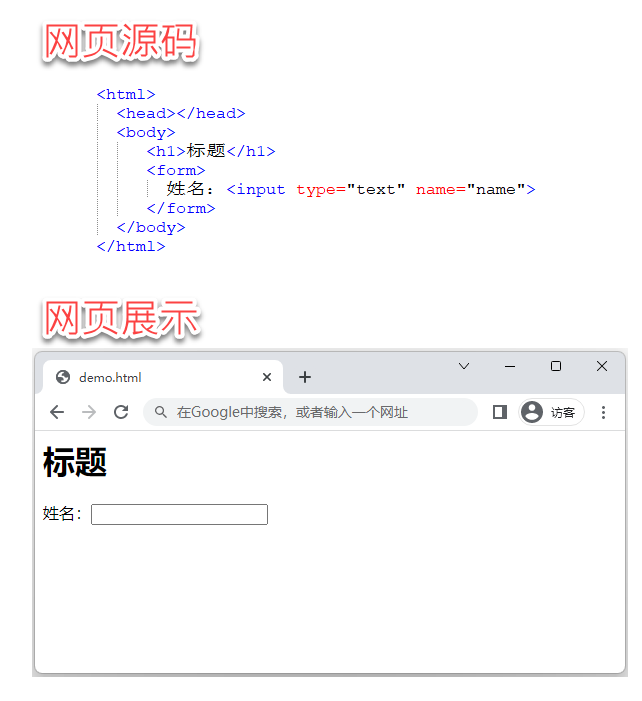
《网页源码与网页展示》
如果我们观察此页面源码,可以发觉,一个网页其实很像一棵树,根节点是<html>,下面有一个子节点 <body>, 再往下还有 <h1> 和 <form> 以及 <input> 三个孙节点。
由此,我们可以得出第一个结论:一个网页本质上是一棵树,树上的每个节点可以称其为“网页元素”,有时也称其为“页面节点”。
3、网页元素的定位
我们知道什么是网页元素了,一个明显的问题是:对一个网页元素如何定位?一般说来有两种办法,一种称之为 Selector,一种称之为 XPath。 什么是 Selector?什么又是 XPath?为了让大家有个感性认识,以刚才的网页为例,如果我们要定位 Edit 输入框的位置,可以按 F12 打开浏览器的开发者工具 DevTools, 选中 Edit 输入框,右键复制其 Selector 或者 XPath:
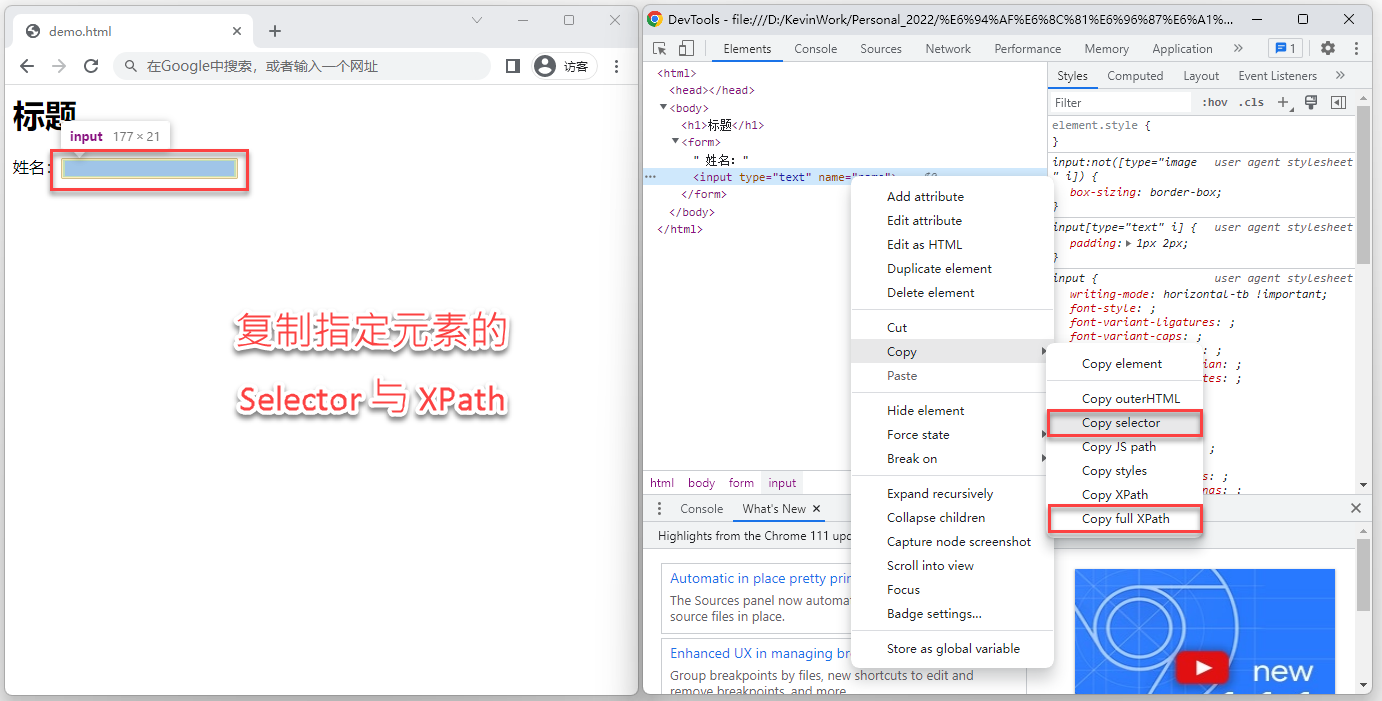
《通过 Selector 或 XPath 对网页元素进行定位》
复制的 Selector 值为:body > form > input[type=text] ,XPath 的值为: /html/body/form/input
由此,我们可以得出第二个结论:网页元素可以通过 Selector 或者 XPath 进行定位。
4、网页元素选择器
无论是 Selector 还是 XPath,对各位同学来说过于晦涩,花漾灵动显然有更好的做法,那就是“网页元素捕获器”。
回到我们的Demo流程,现在要在百度首页中检索“花漾灵动”,请在页面中拖入“输入内容”节点,显然,我们需要定位百度首页的“搜索框”节点, 请点击“从元素库中选择”,如下图所示:
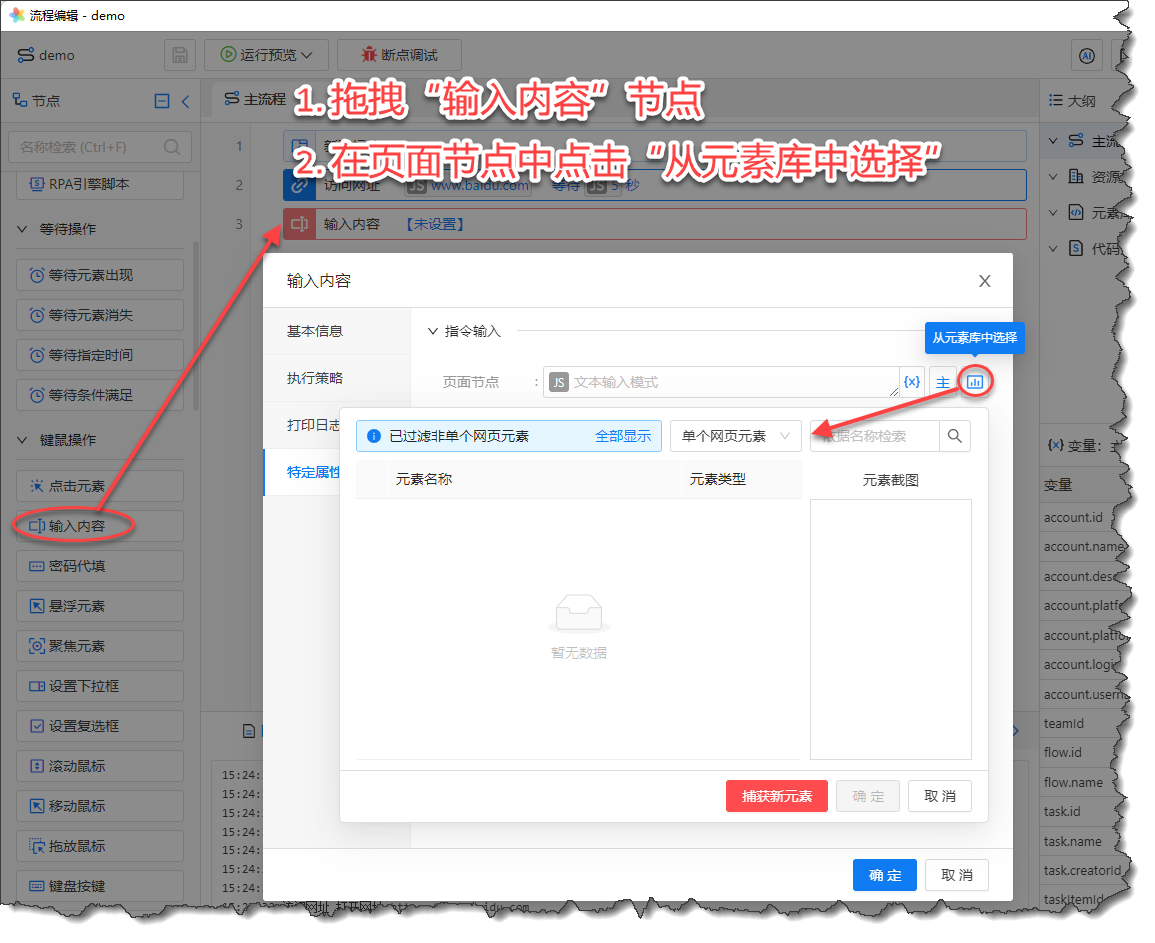
《从元素库中选择网页元素》
由于目前元素库是空的,请点击“捕获新元素”,系统会弹出“元素捕获器”,当鼠标在百度首页中移动时,会自动高亮选中的节点,如下图所示:
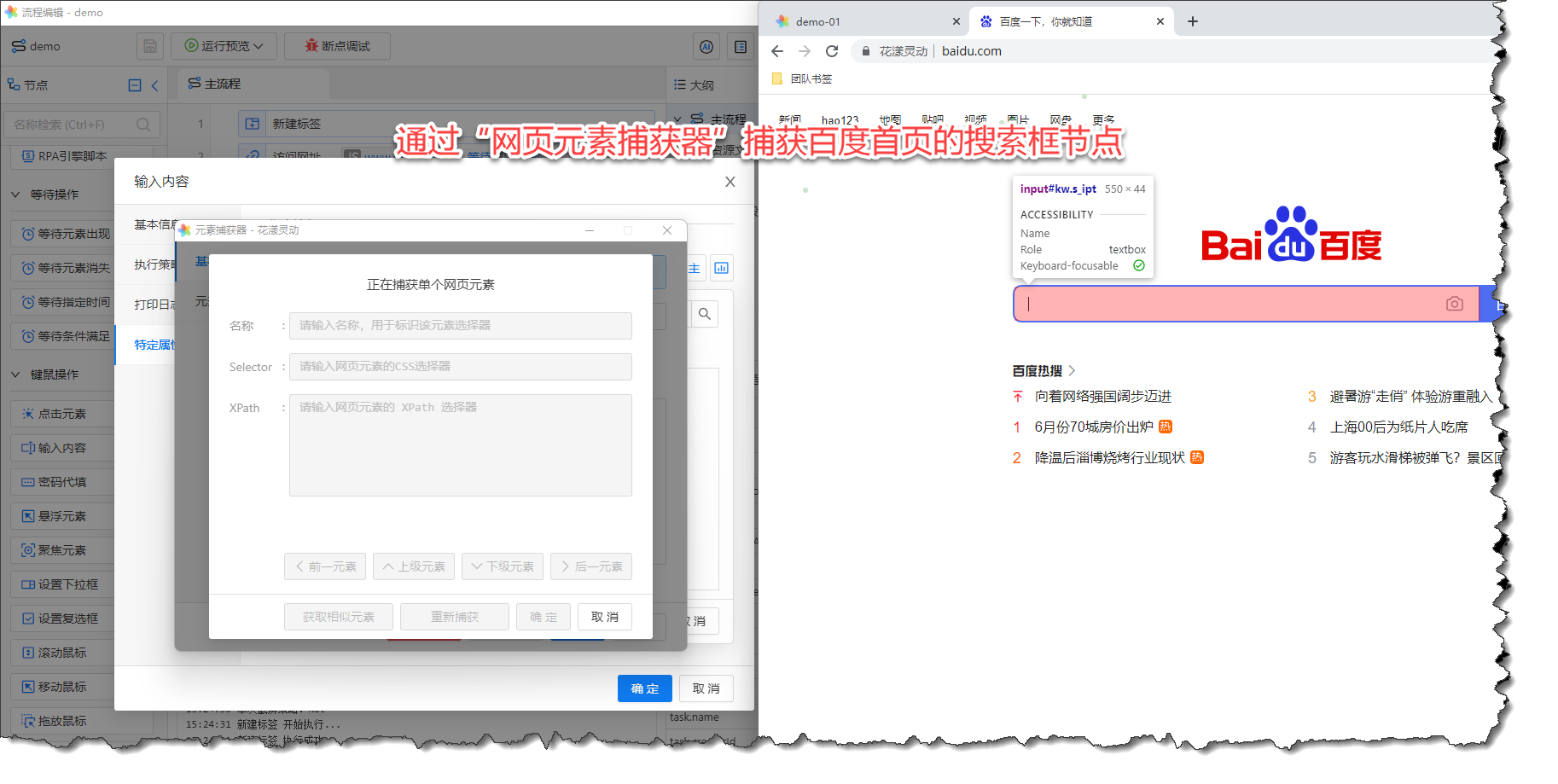
《通过“元素捕获器”来捕获页面节点》
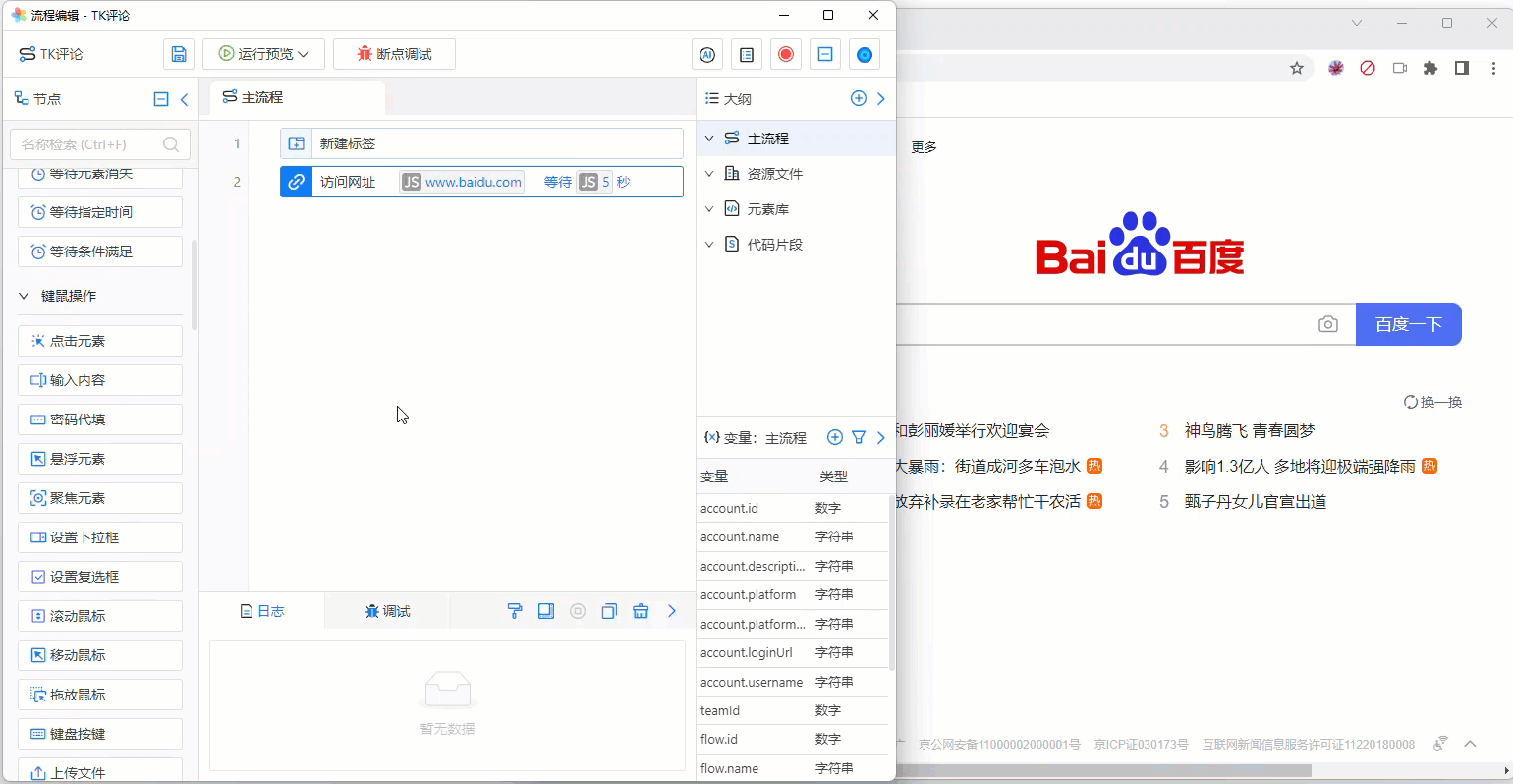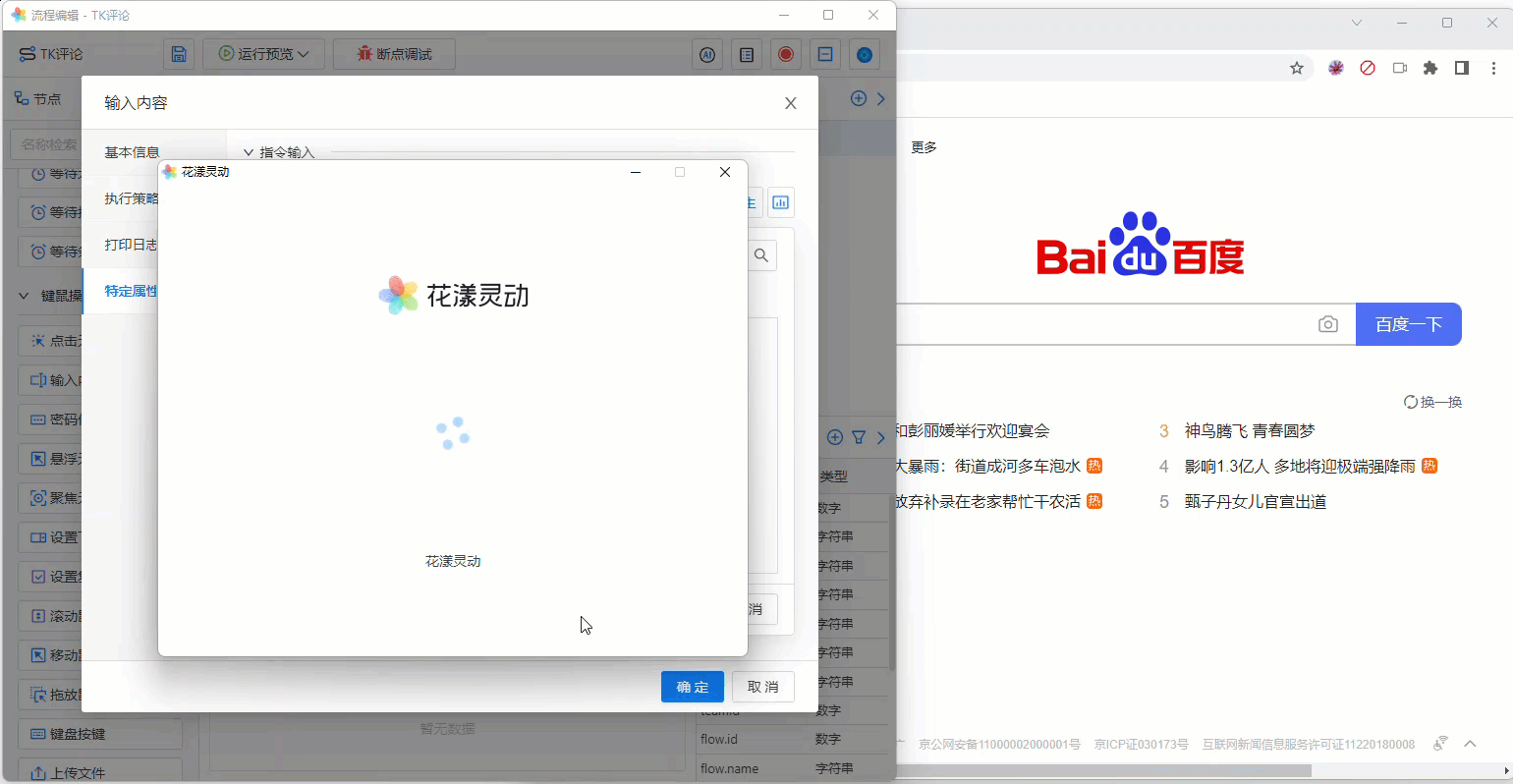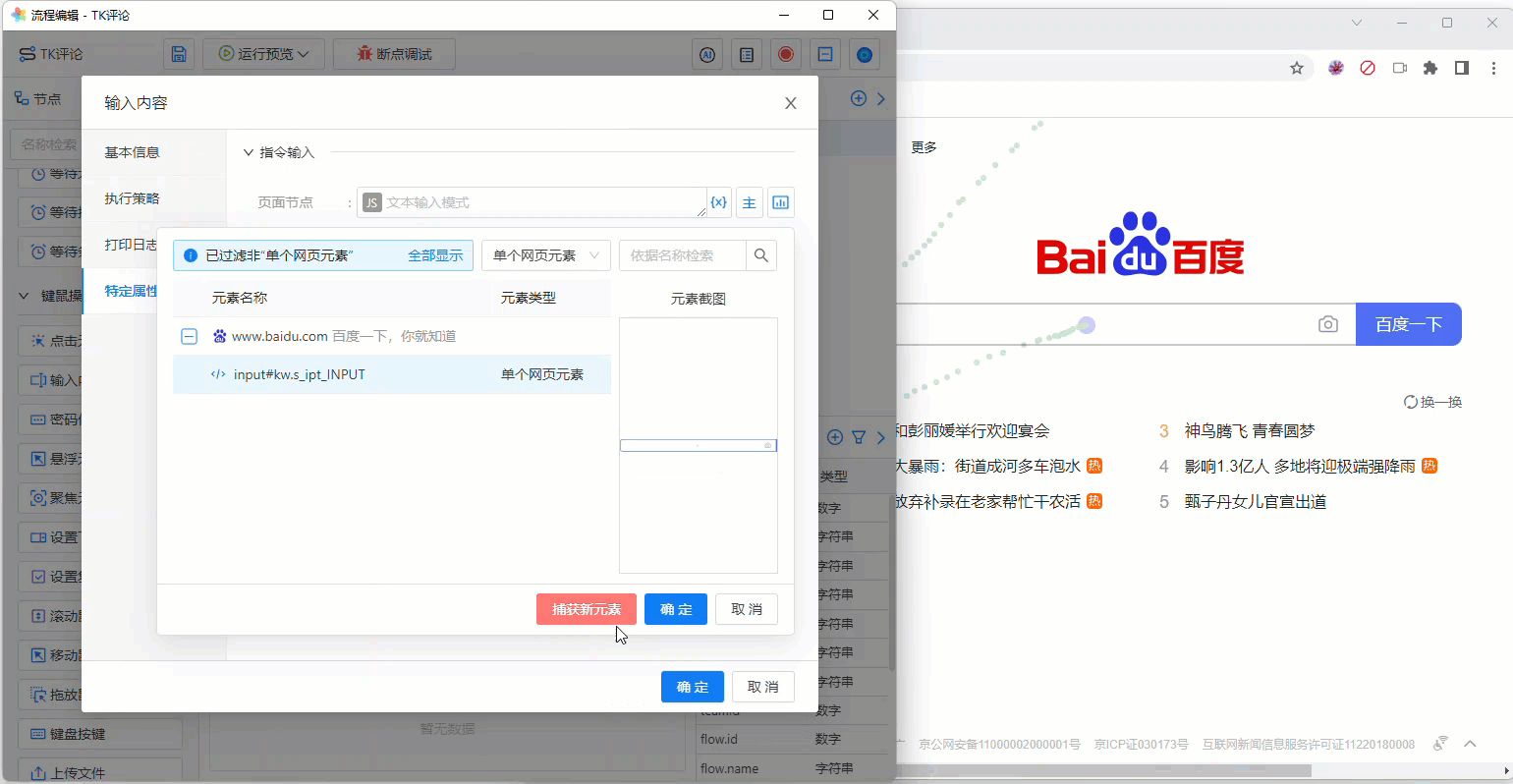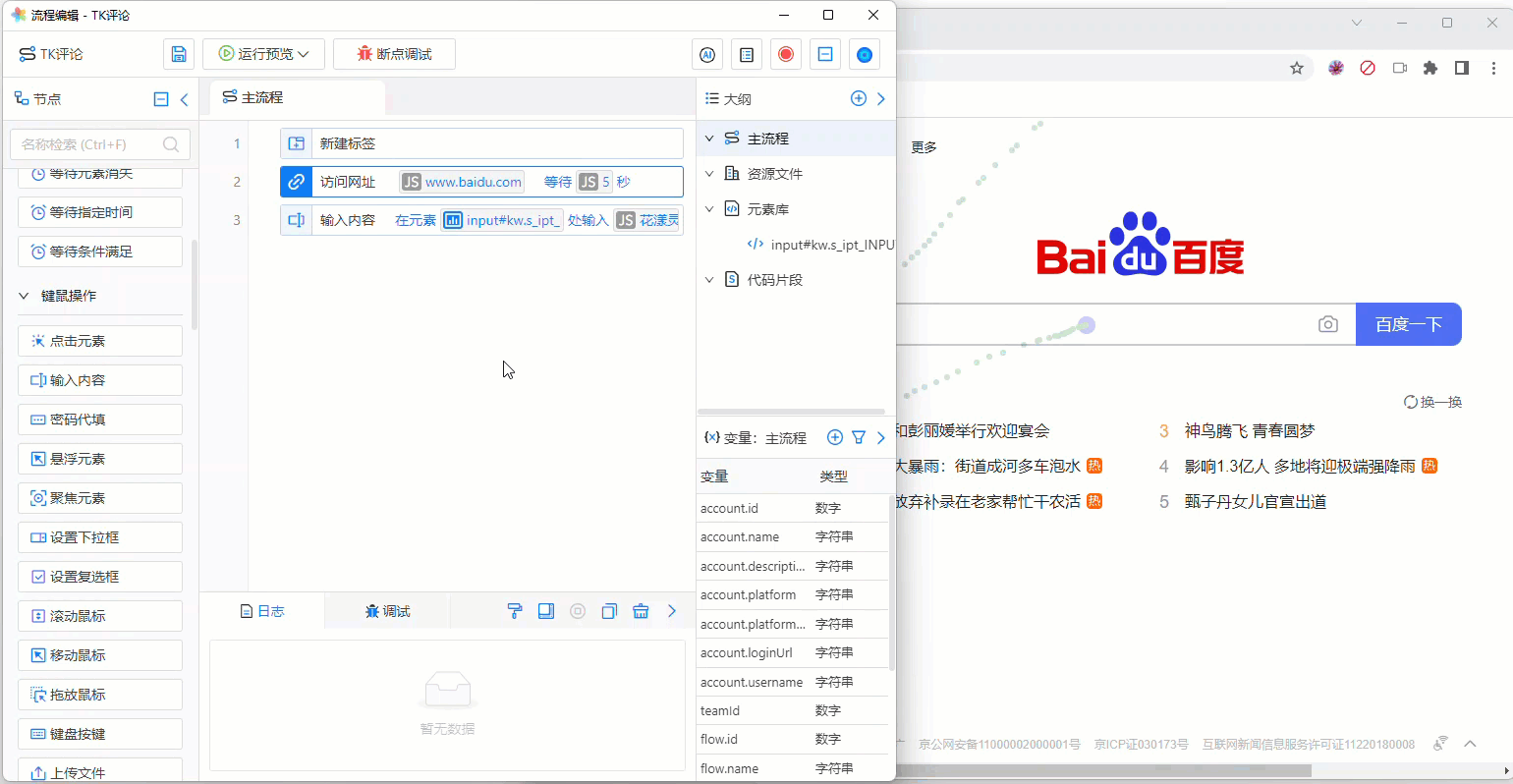
当我们点击百度首页的搜索框时,元素捕获器会自动获取该页面节点的 Selector 与 XPath,换言之,您无需了解 Selector/XPath 这些晦涩的知识, 只需要通过花漾为您提供的“元素捕获器”捕获到您需要定位的网页元素即可。
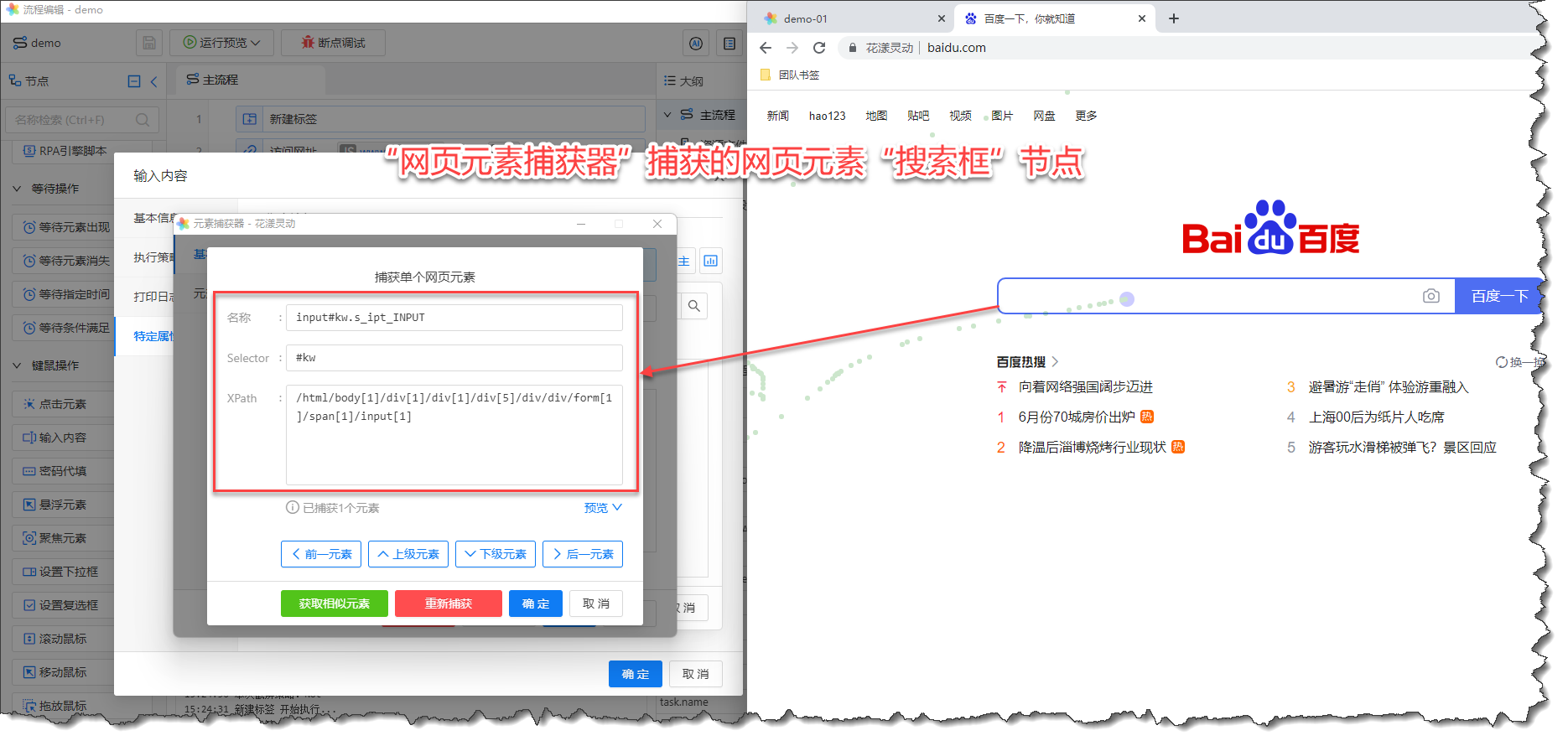
《捕获的百度搜索框节点》
当元素被捕获后,您可以为其起一个方便记忆的名称,点击“确定”,该网页元素将存储到本流程的“元素库”中:
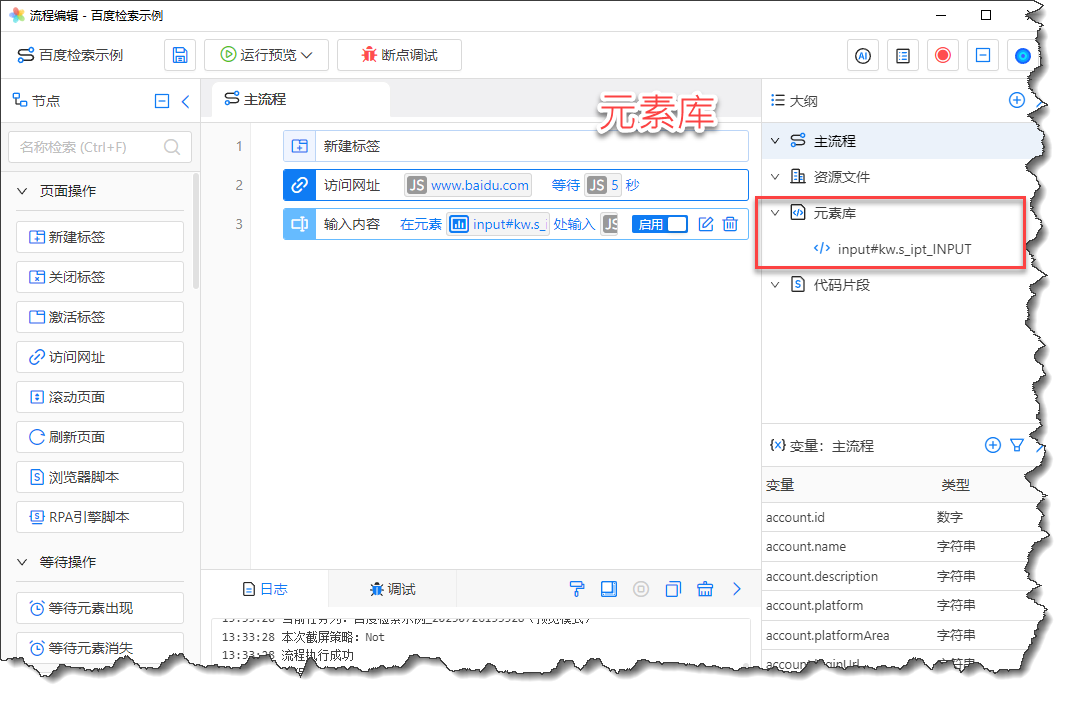
《元素库》
请在流程节点“输入内容”中设置以下选项:页面节点选择刚刚捕获的网页元素,输入值输入“花漾灵动”:
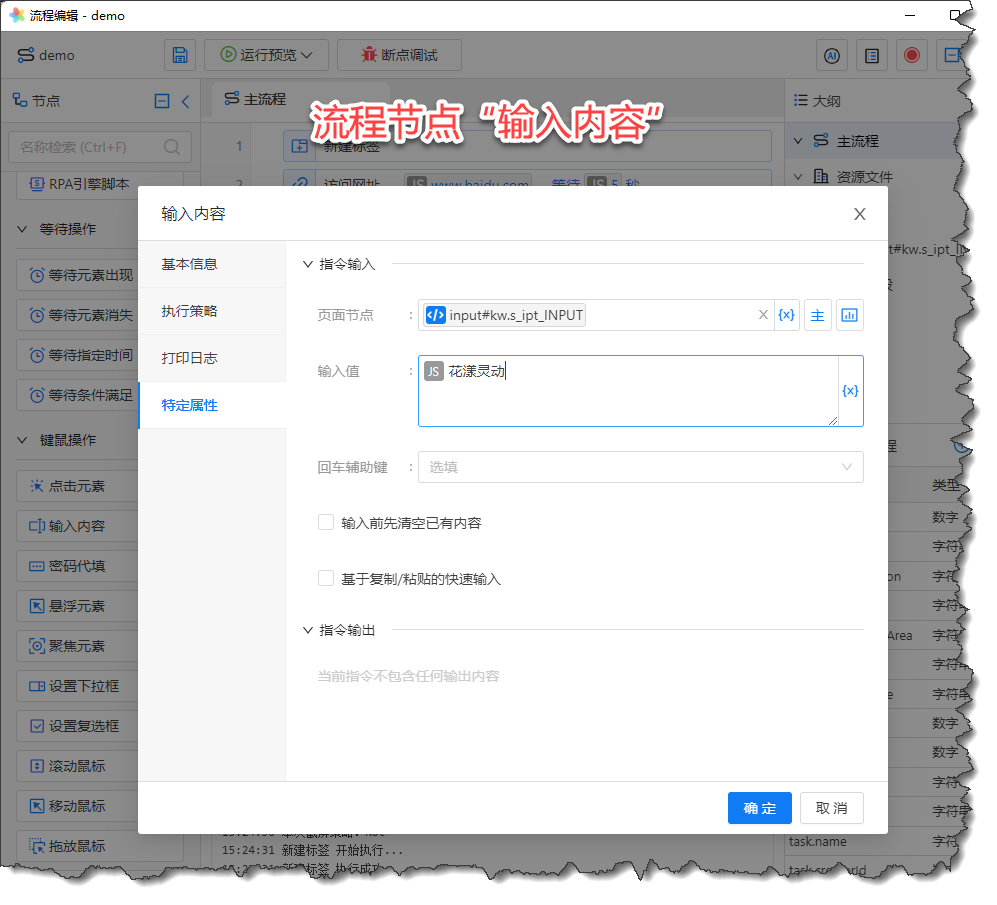
《流程节点“输入内容”》
为方便您的理解,请您观察以下GIF动画:
《捕获search框》
最后,请往流程中拖入节点“键盘按钮”,并选择“回车键”:
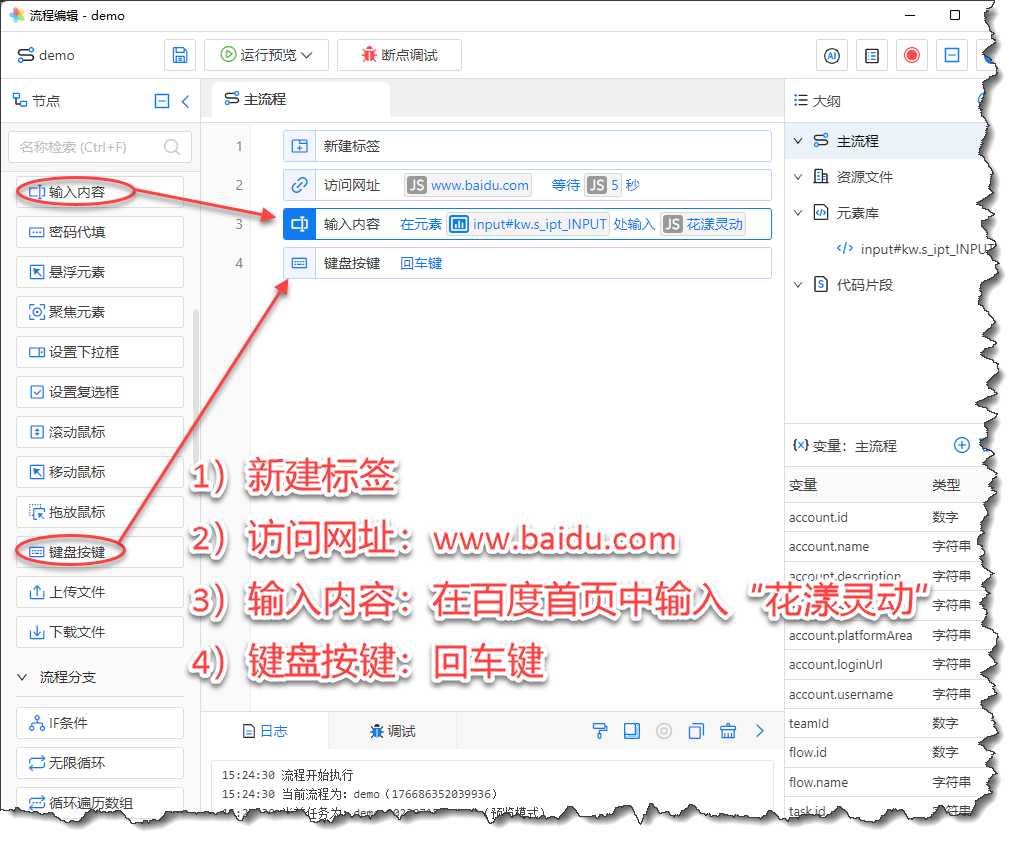
《本流程的完整内容》
至此,本流程编辑完成,现在可以通过点击“运行预览”,观察流程的执行效果:
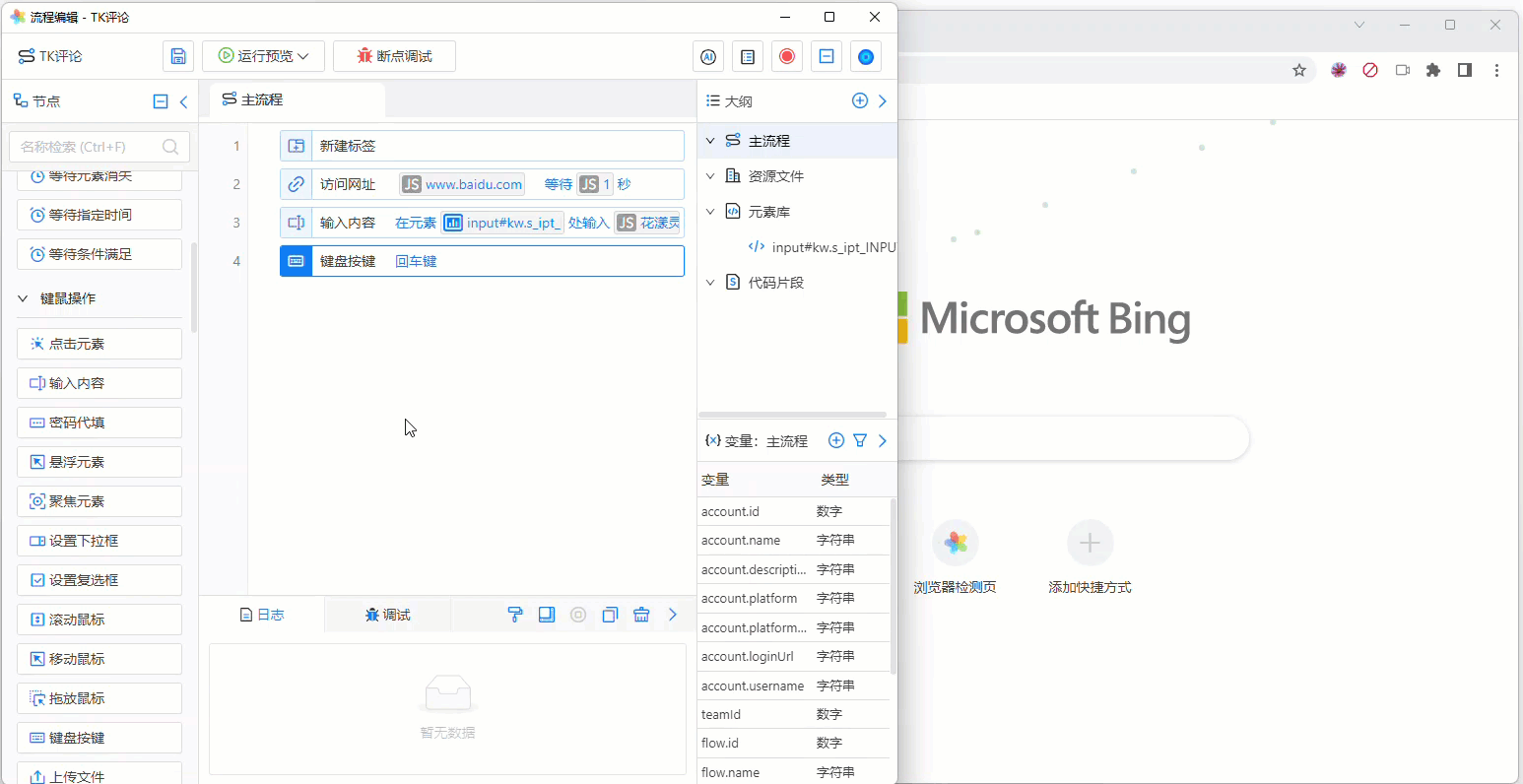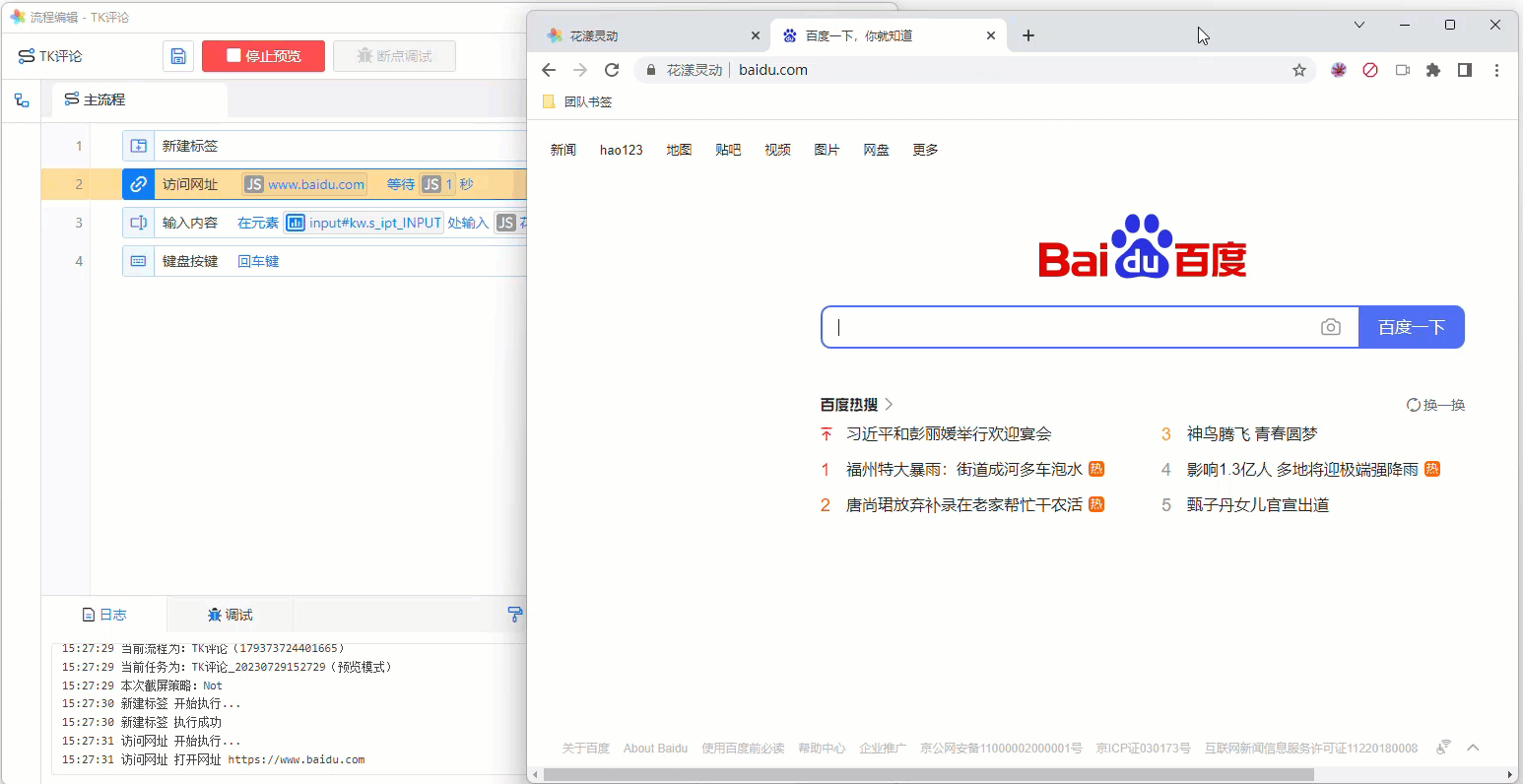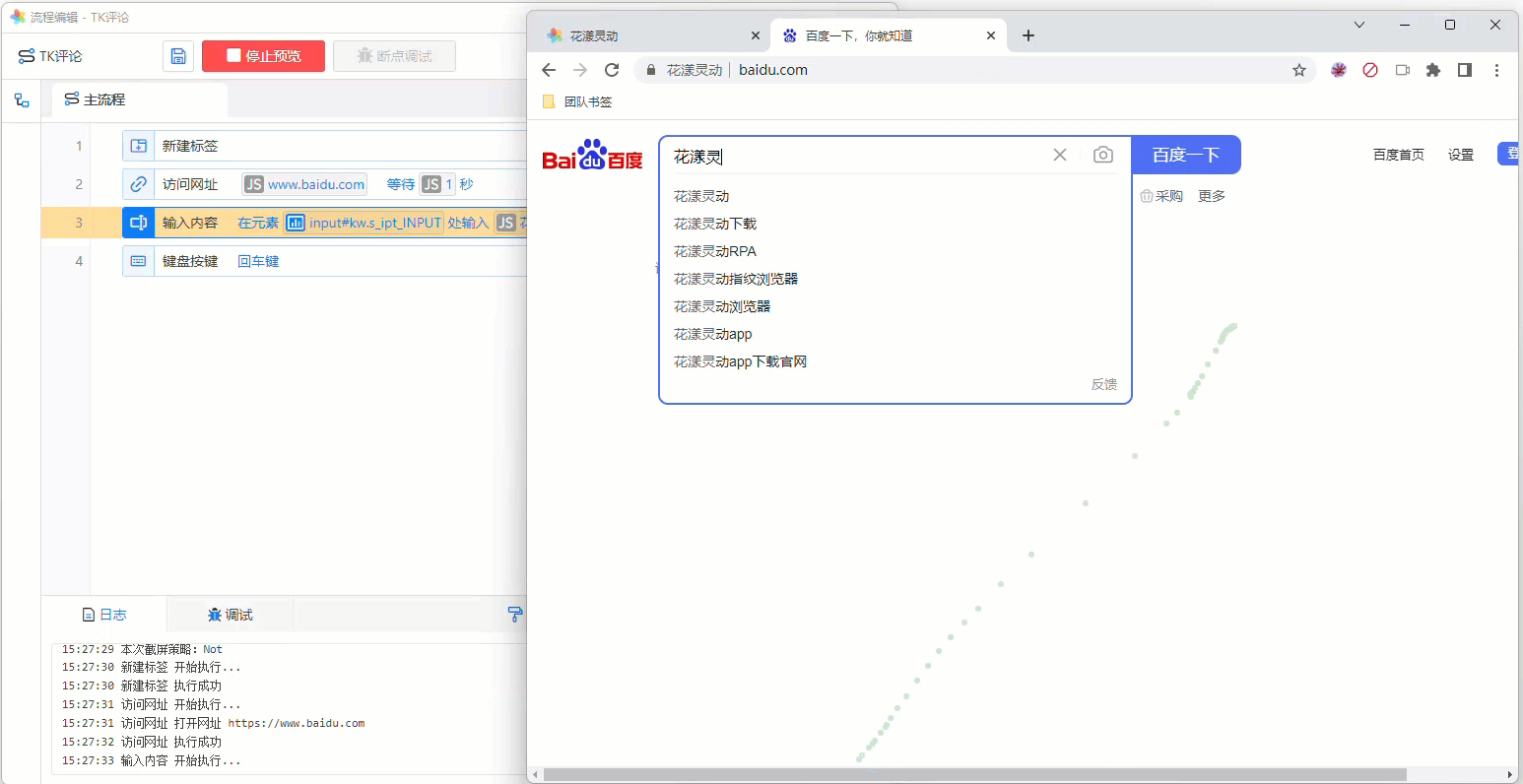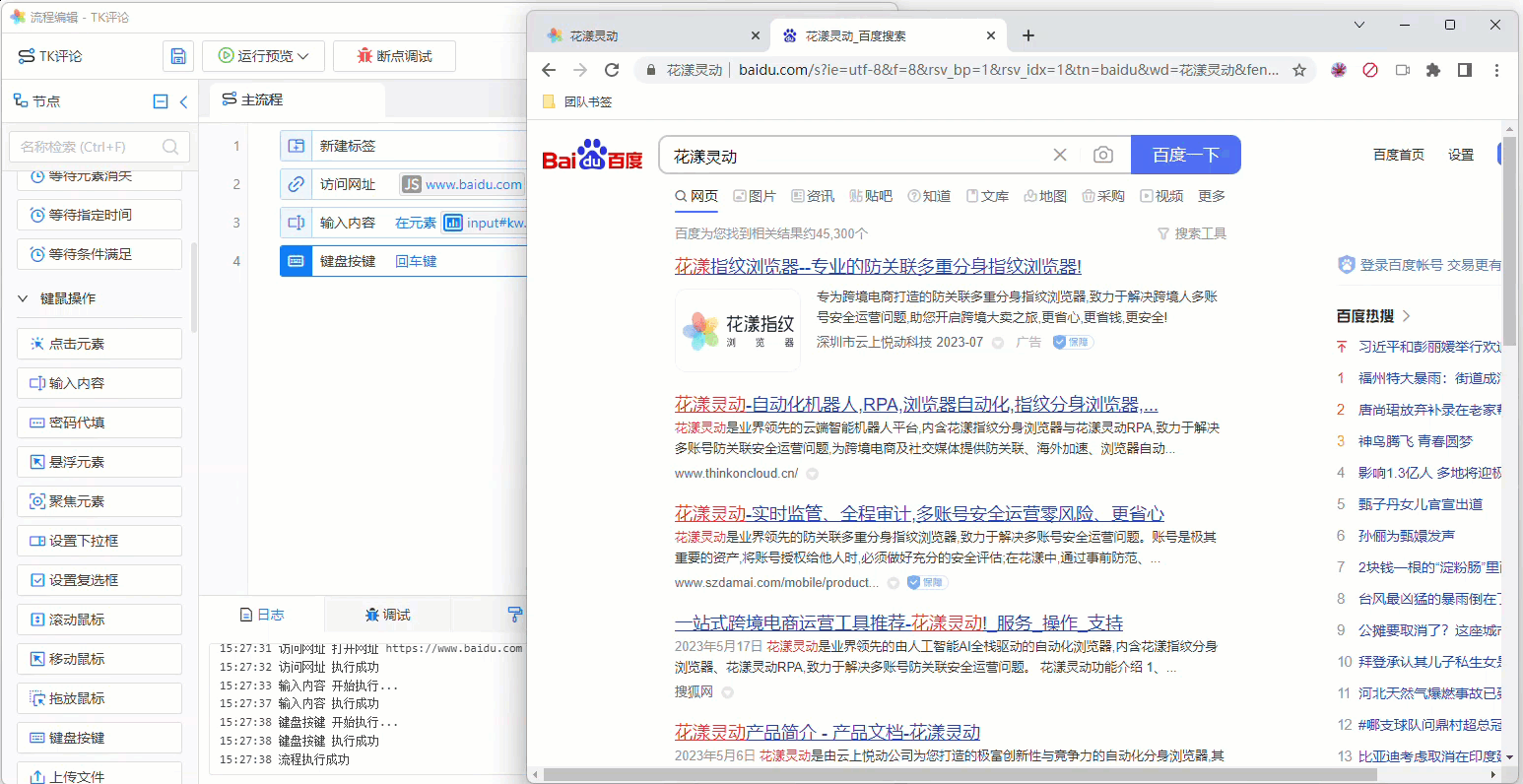
《本流程的执行效果》
5、总结
本文带领大家了解了什么是网页元素,以及如何通过“元素捕获器”定位网页中的页面节点。关于网页元素更进一步的介绍可以阅读 网页元素与元素捕获器 一文。
在本文中,我们在流程中直接写死检索的关键词 “花漾灵动” , 显然,这样写出来的流程过于呆板,我们应该允许用户检索不同的关键词,为了达成此目标,我们需要引入一个新的概念: 变量 , 请大家继续阅读下一章节 一个简单的示例:变量 。
最后,针对《一个简单的示例》系列文章所介绍的内容,我们为您准备了以下视频教程,辅助您了解相关内容:


