网页元素与元素捕获器
1、前言
我们在编写和浏览器相关的流程时,一个很自然的问题是:如何对网页上的控件进行定位?举例,我们需要点击某个按钮,如何定位此按钮的位置? 显然,我们不可能使用类似坐标的概念,因为当浏览器窗口大小发生变化时,该按钮的坐标位置很容易发生变动。 花漾灵动的解决方案是:针对浏览器页面,我们引入一个称之为 “网页元素” 的概念,本文将向大家详细介绍关于网页元素以及元素捕获器的使用等相关知识。
2、关于网页元素
什么是网页元素?下图是一个非常简单的网页源码以及用浏览器访问此网页的展示效果:
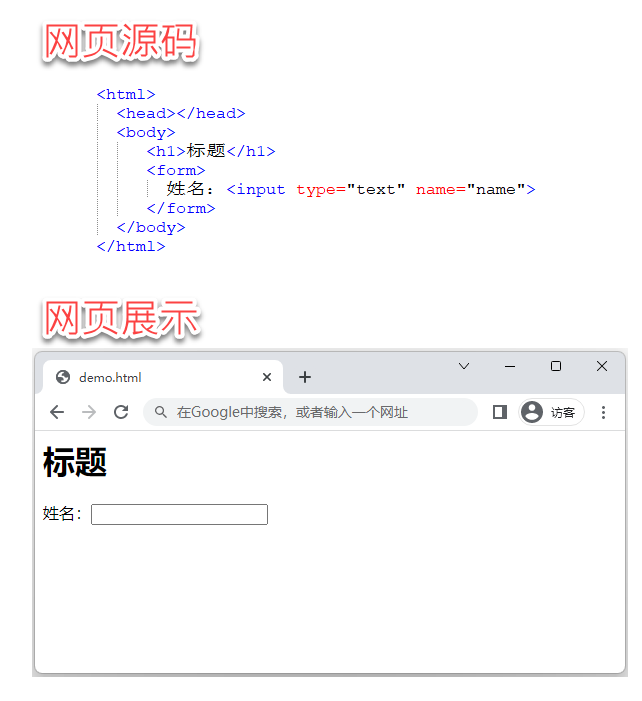
《网页源码与网页展示》
观察此页面源码,可以发觉,一个网页其实很像一棵树,根节点是 <html>,下面有一个子节点 <body>,
再往下还有 <h1> 和 <form> 以及 <input> 三个孙节点。
由此,我们可以得出第一个结论:一个网页本质上是一棵树,树上的每个节点可以称其为“网页元素”,有时也称其为“页面节点”。
3、网页元素的定位
新的问题来了:如何定位一个网页元素?对 Web开发人员来说,一般有两种办法,一种称之为 Selector,一种称之为 XPath。 什么是 Selector,什么又是 XPath?为了让大家有个感性认识,以上述网页为例,如果我们要定位 Edit 输入框的位置,可以按 F12 打开浏览器的开发者工具 DevTools, 选中 Edit 输入框,右键复制其 Selector 或者 XPath:
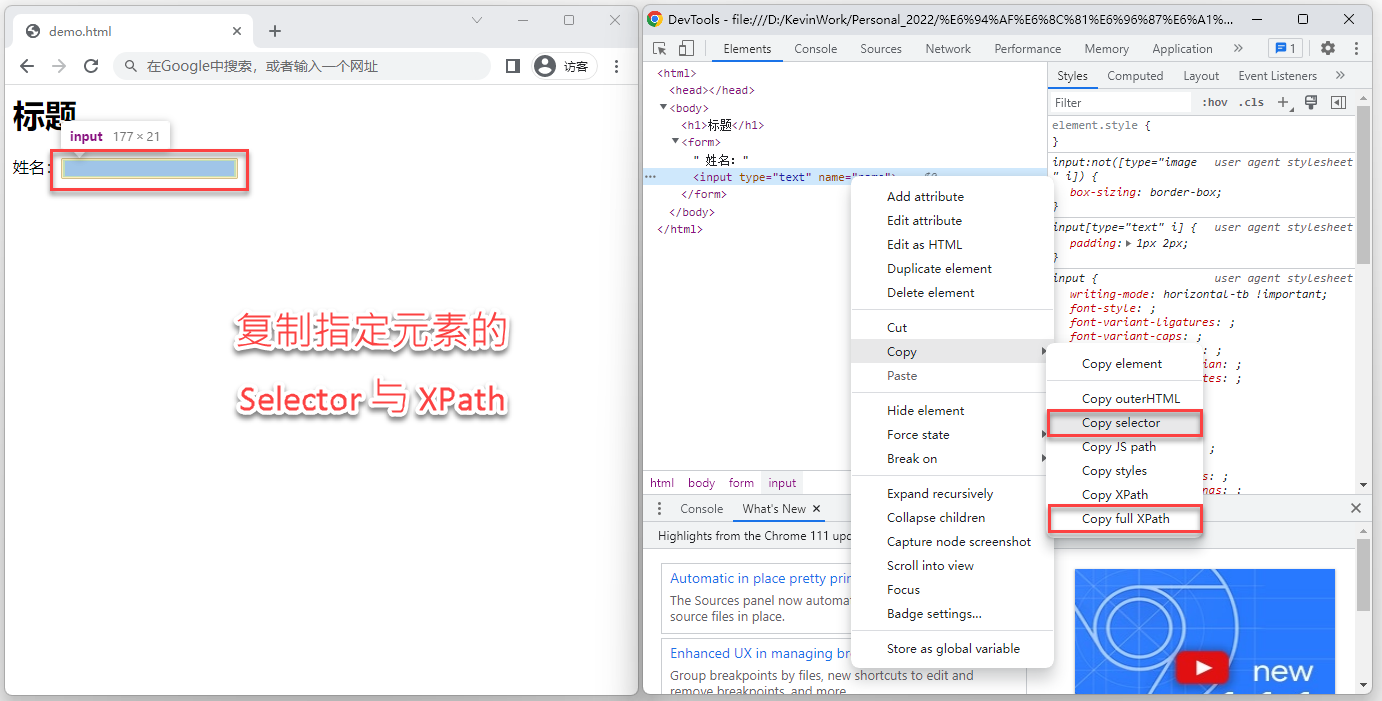
《通过 Selector 或 XPath 对网页元素进行定位》
复制的 Selector 值为:body > form > input[type=text] ,XPath 的值为: /html/body/form/input
由此,我们可以得出第二个结论:网页元素可以通过 Selector 或者 XPath 进行定位。
4、网页元素捕获器
显然,各位同学未必都是Web开发人员,无论是 Selector 还是 XPath,对我们来说过于晦涩,花漾灵动有更好的做法,那就是“网页元素捕获器”, 通过网页元素捕获器,能够方便我们快速的定位网页元素并获得它的 Selector 与 XPath。
每个流程定义都会有一个“元素库”,里面存储着在该流程中已经捕获的所有网页元素,下面是元素库的截图:
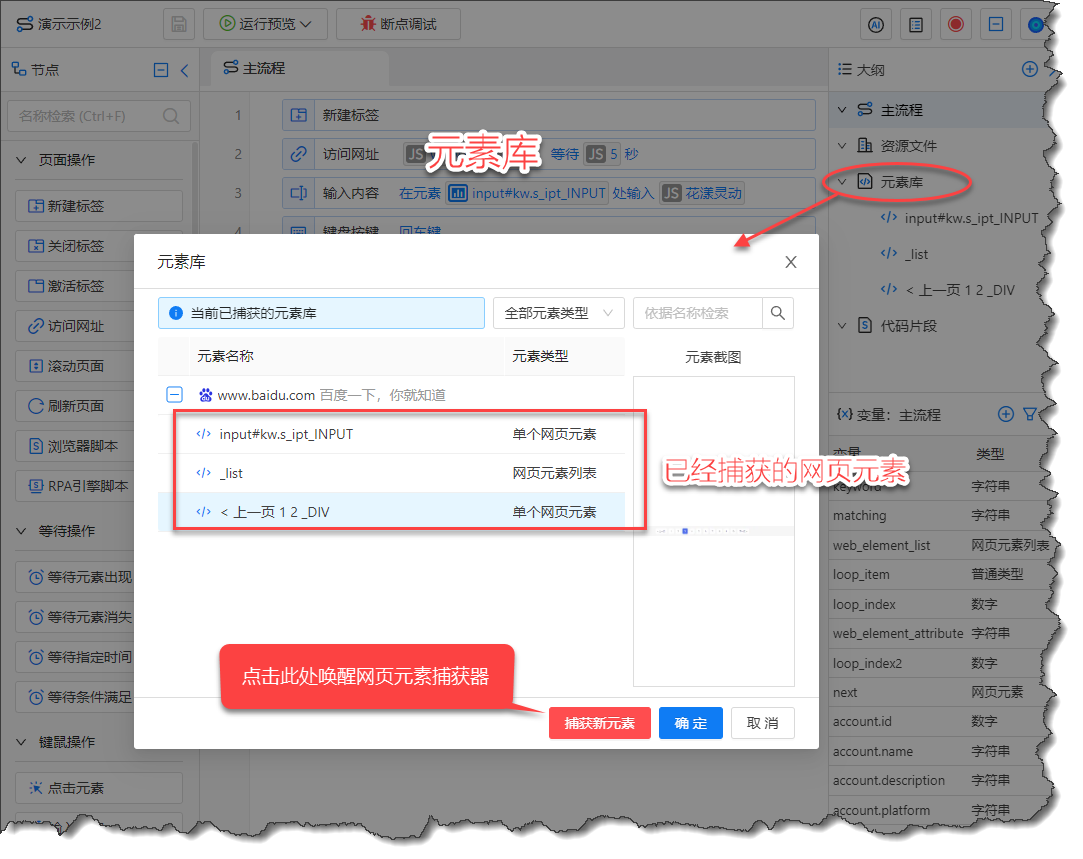
《网页元素库》
在元素库中点击“捕获新的元素”,即可唤醒网页元素捕获器,一个已经捕获的网页元素显示如下:
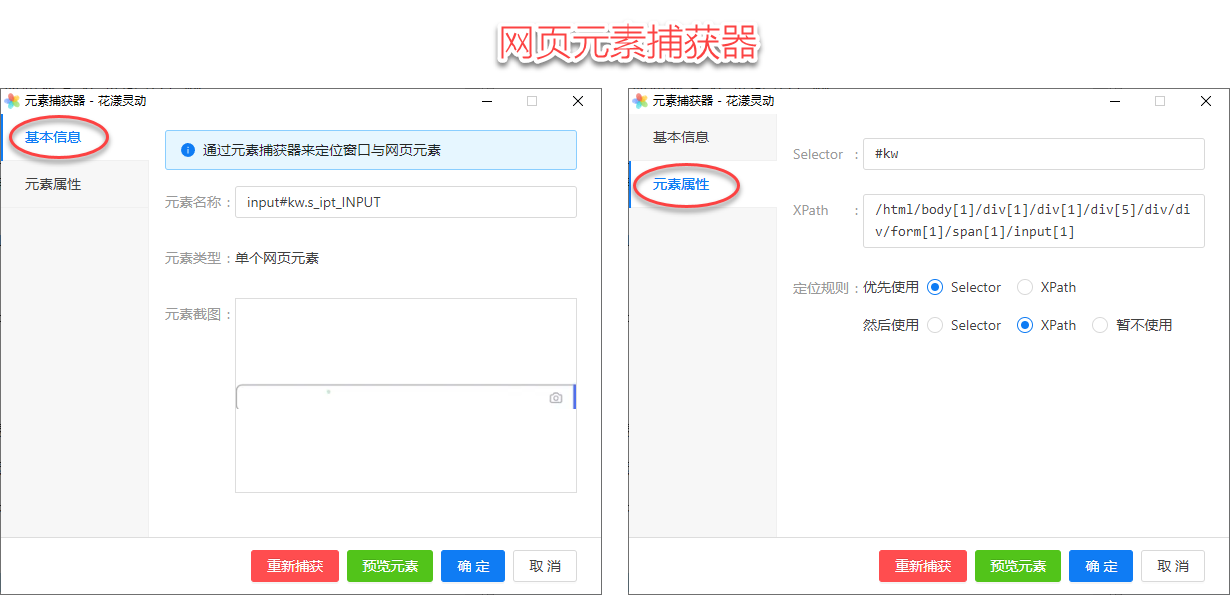
《网页元素捕获器》
5、捕获单个网页元素
下面向大家介绍如何捕获单个网页元素。以百度首页为例,假定我们要捕获 “search框” 这个网页元素,如下图所示:
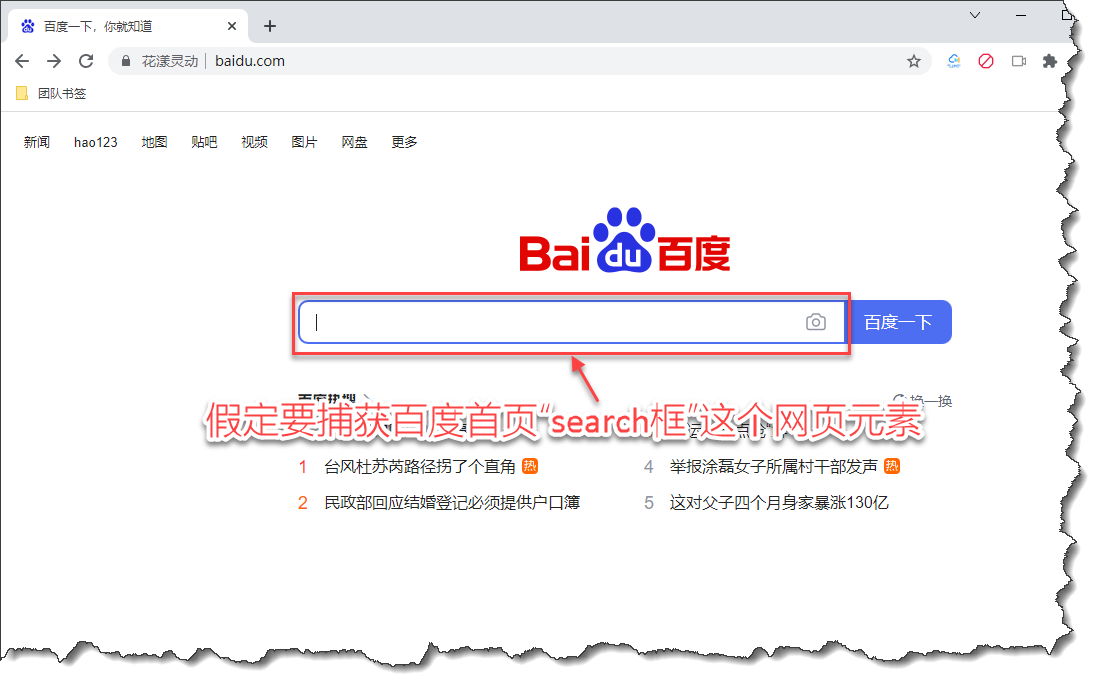
《拟捕获百度首页“search框”元素》
其操作步骤如下:
- 通过元素库唤醒“元素捕获器”
- 选中并点击百度首页“search框”
- 此时,元素捕获器即可显示刚刚选中的网页元素
为方便您的理解,请参考下述GIF动画:
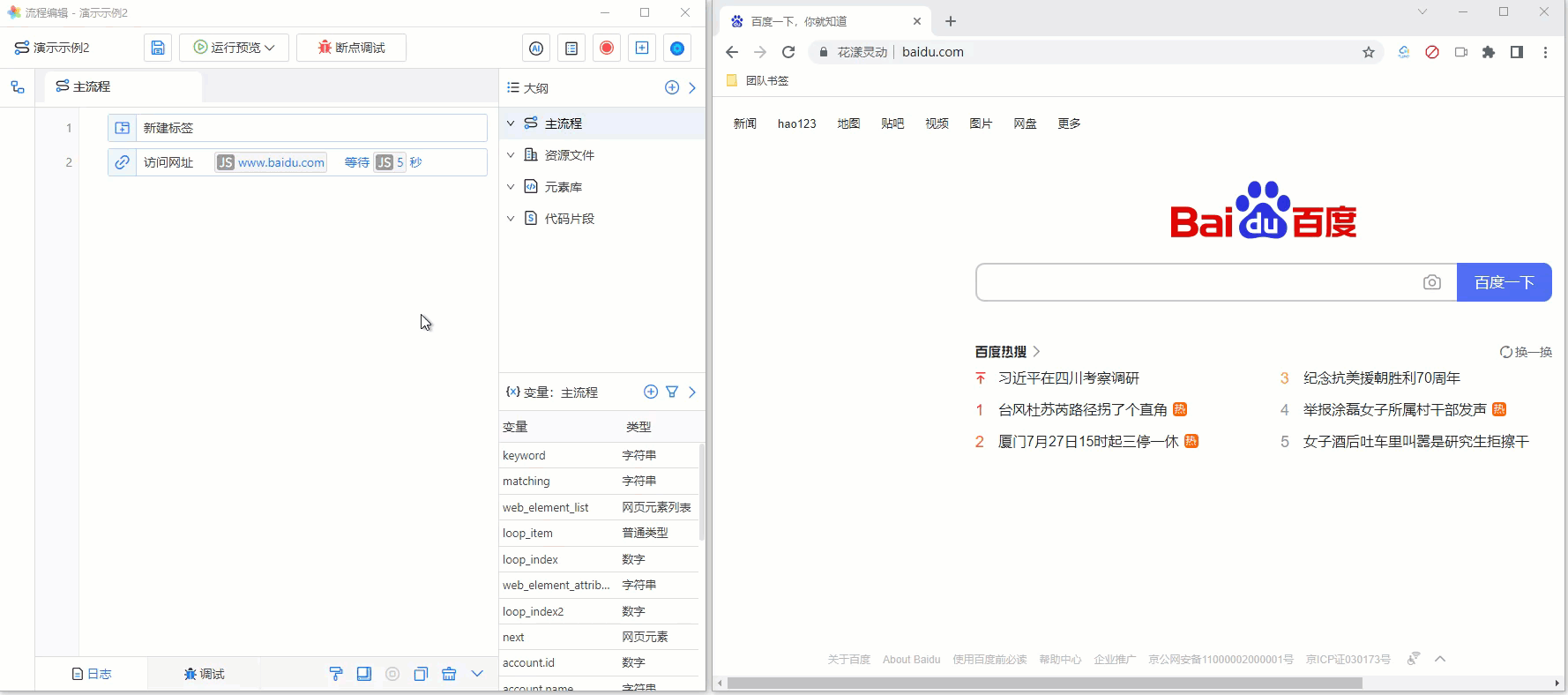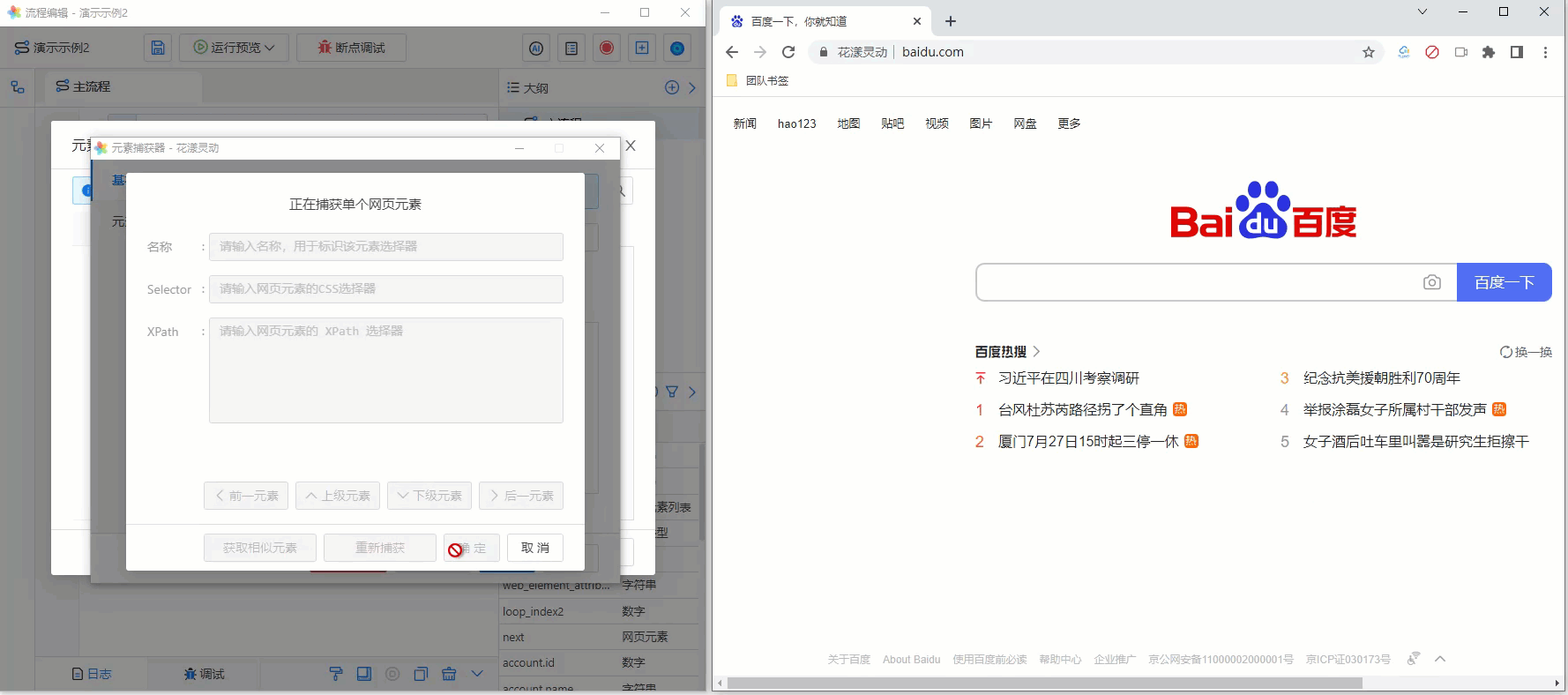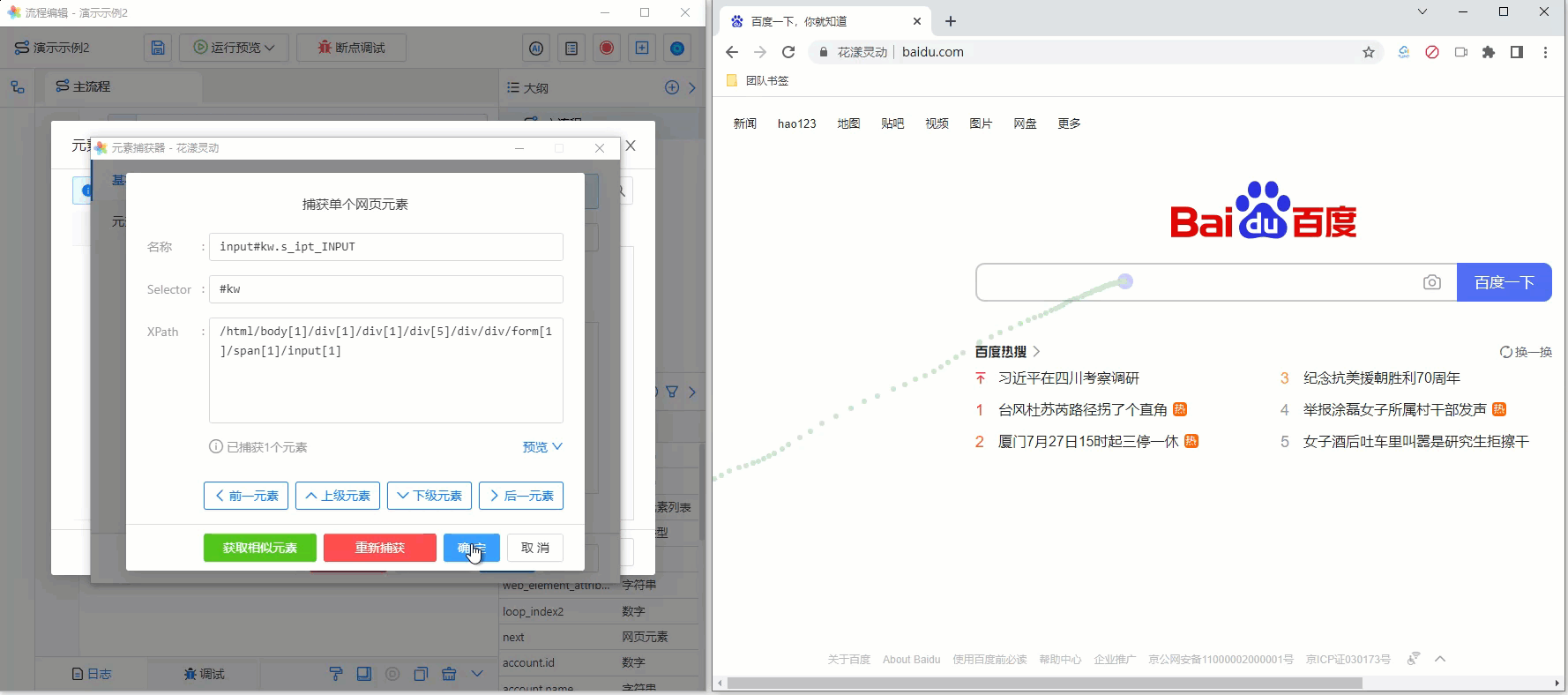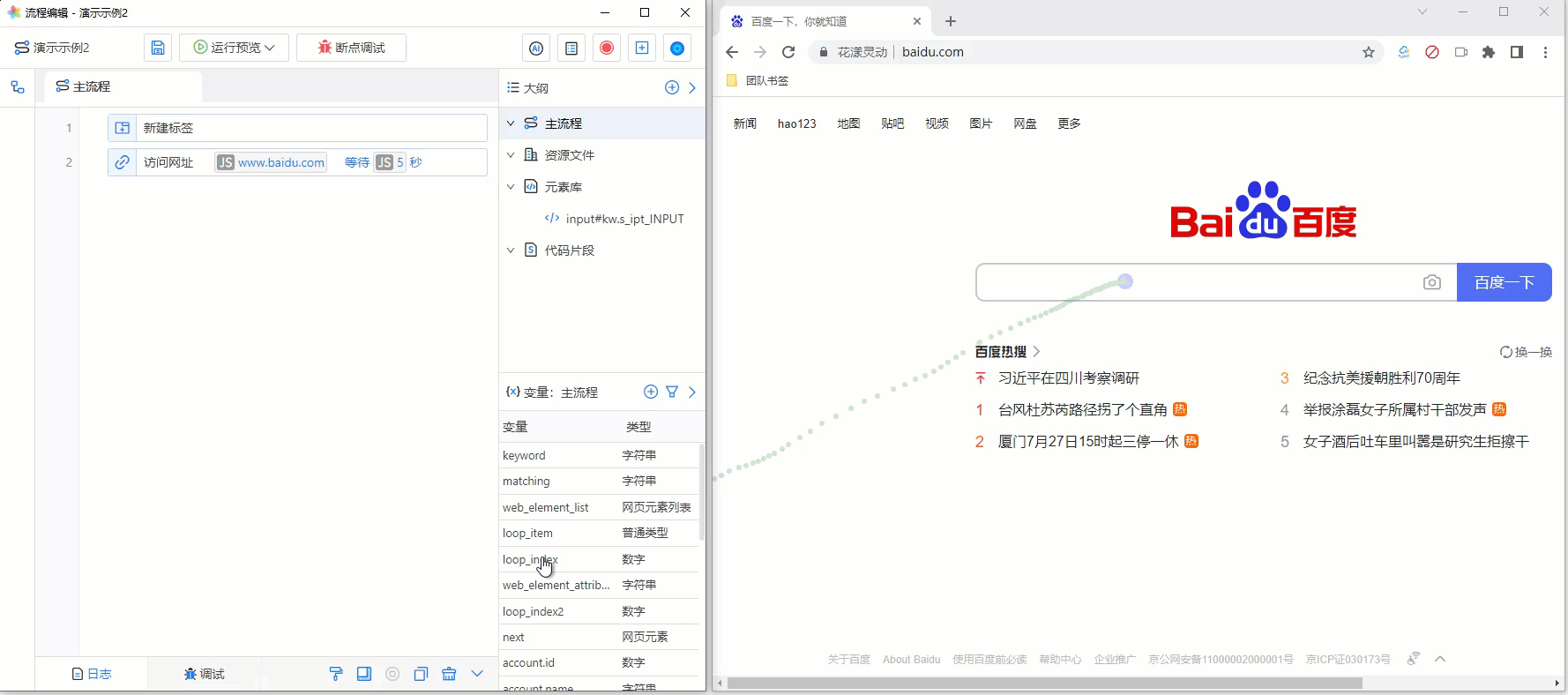
《捕获单个网页元素》
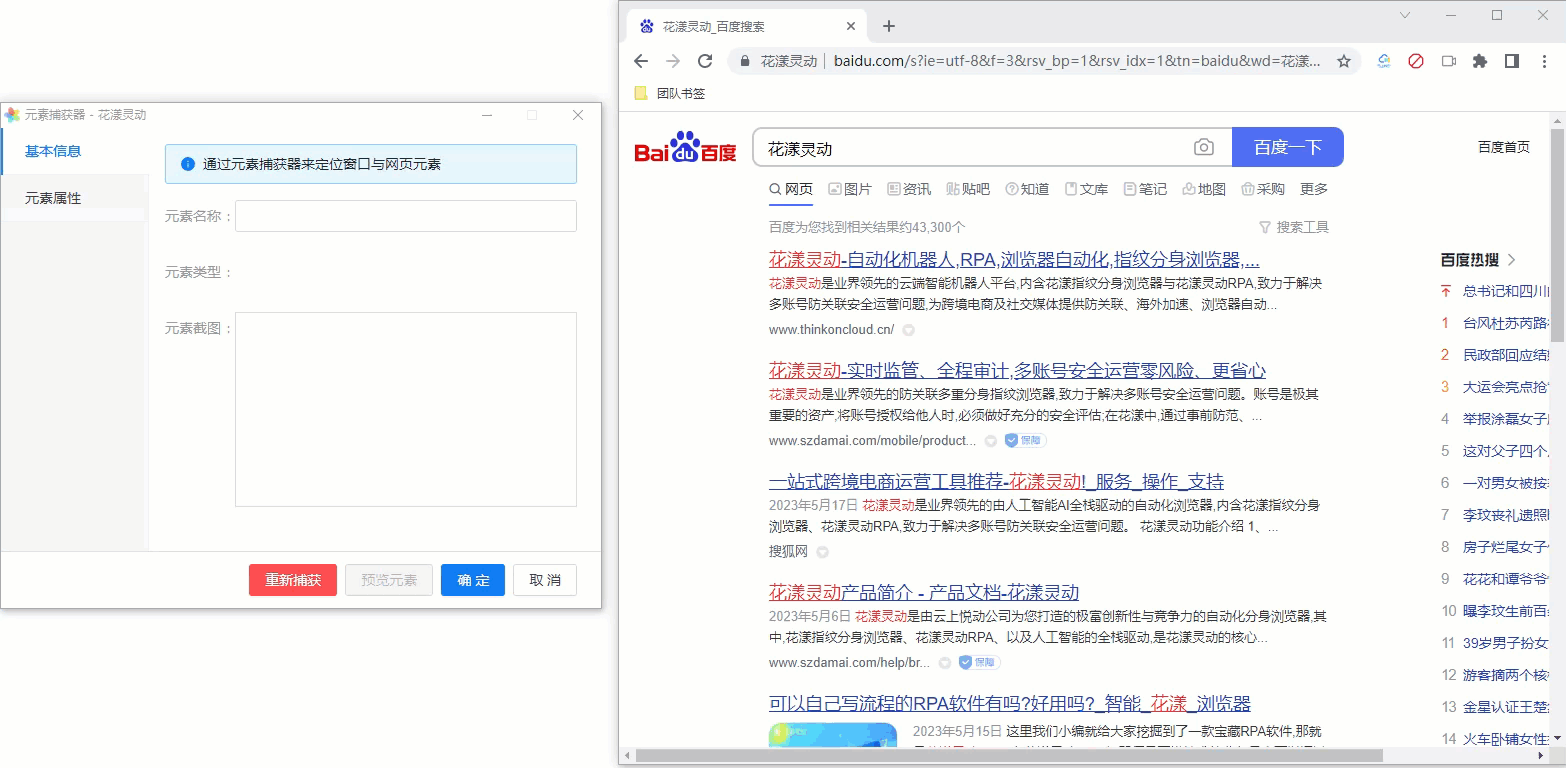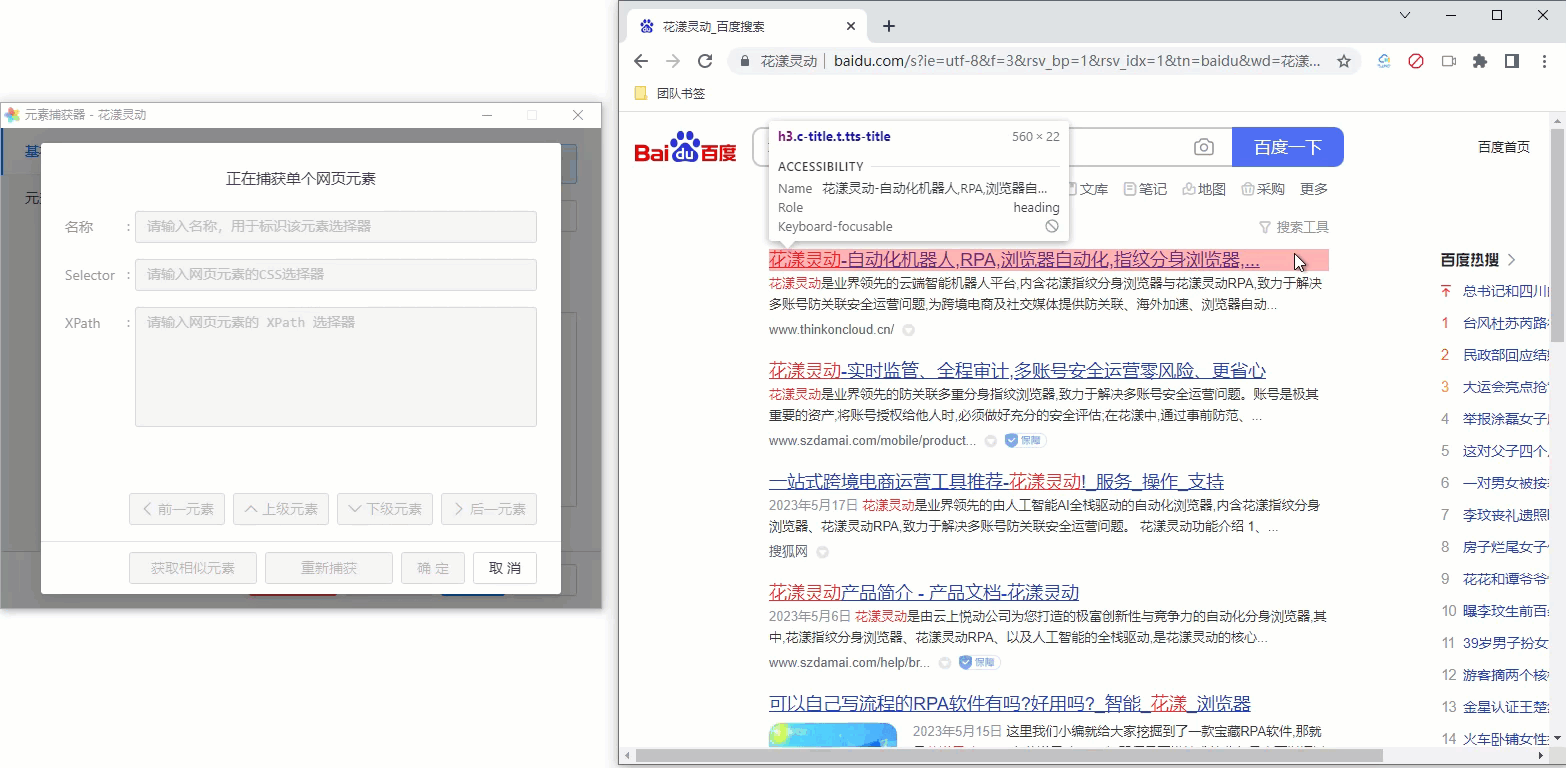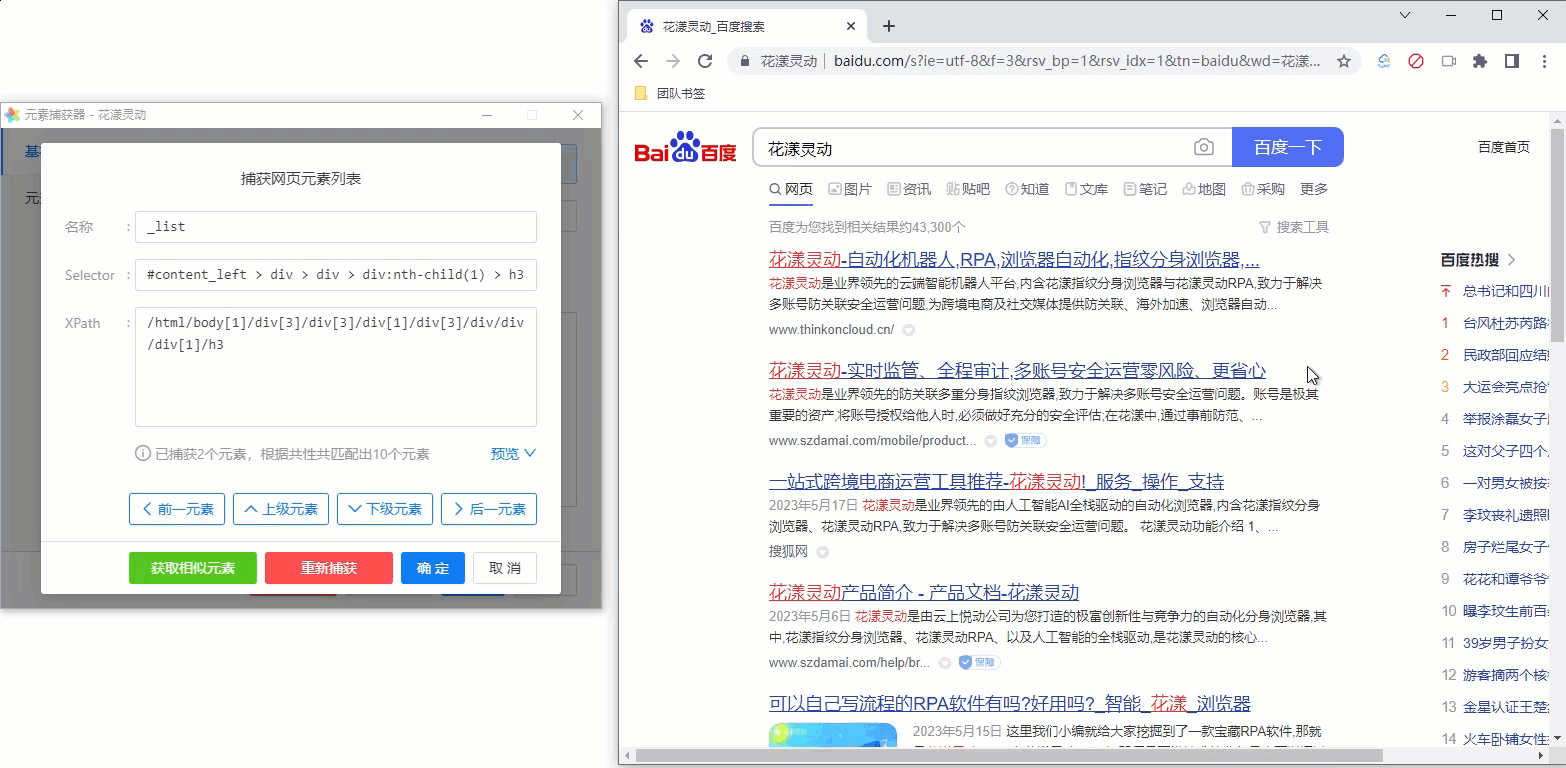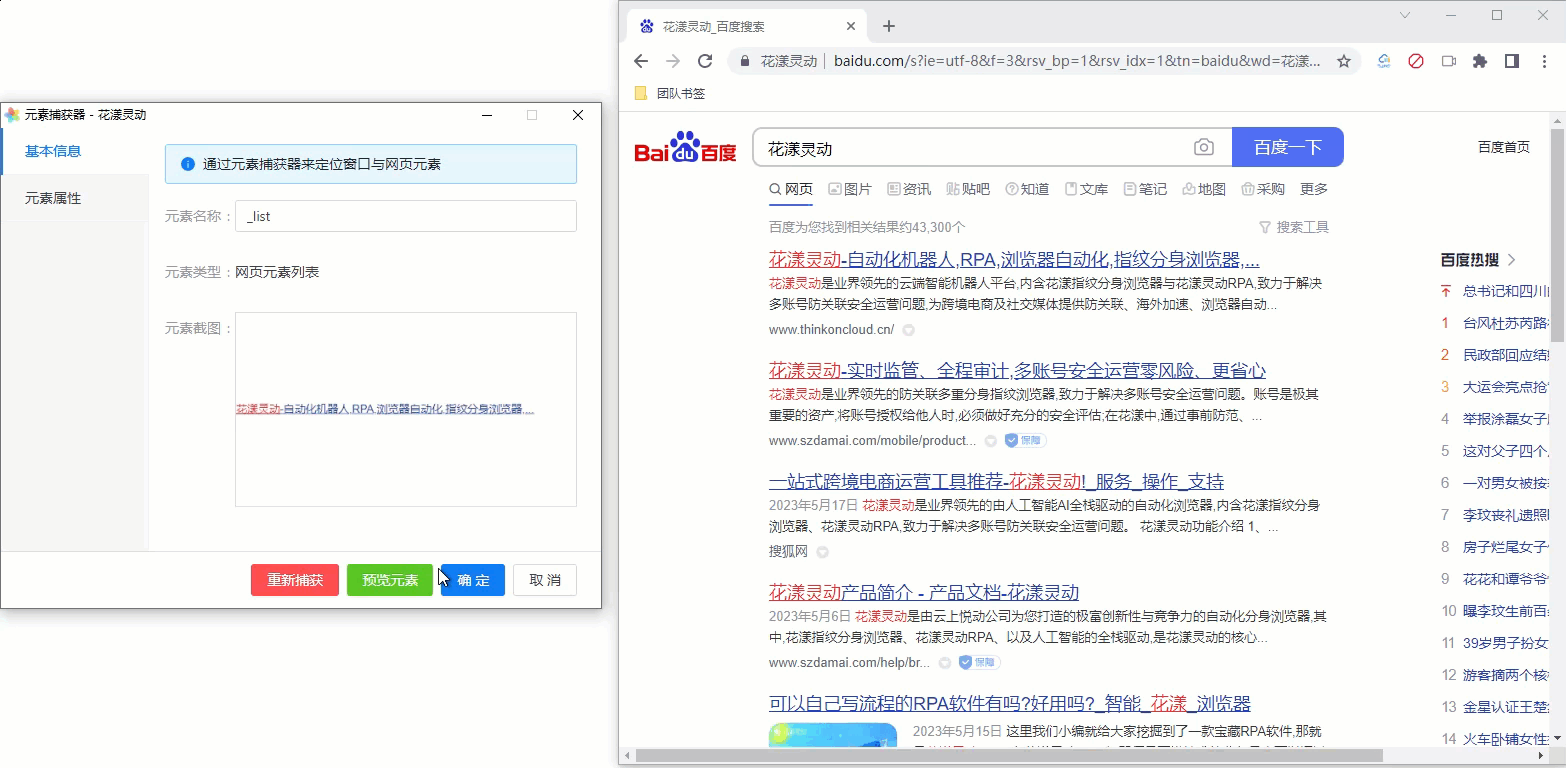
6、捕获网页元素列表
有时候我们需要捕获网页元素列表,举例,针对百度的搜索结果页面,我们希望循环遍历每个搜索结果的标题,此时, 需要把当前页面的所有搜索结果标题作为一个网页元素列表进行捕获,如下图所示:
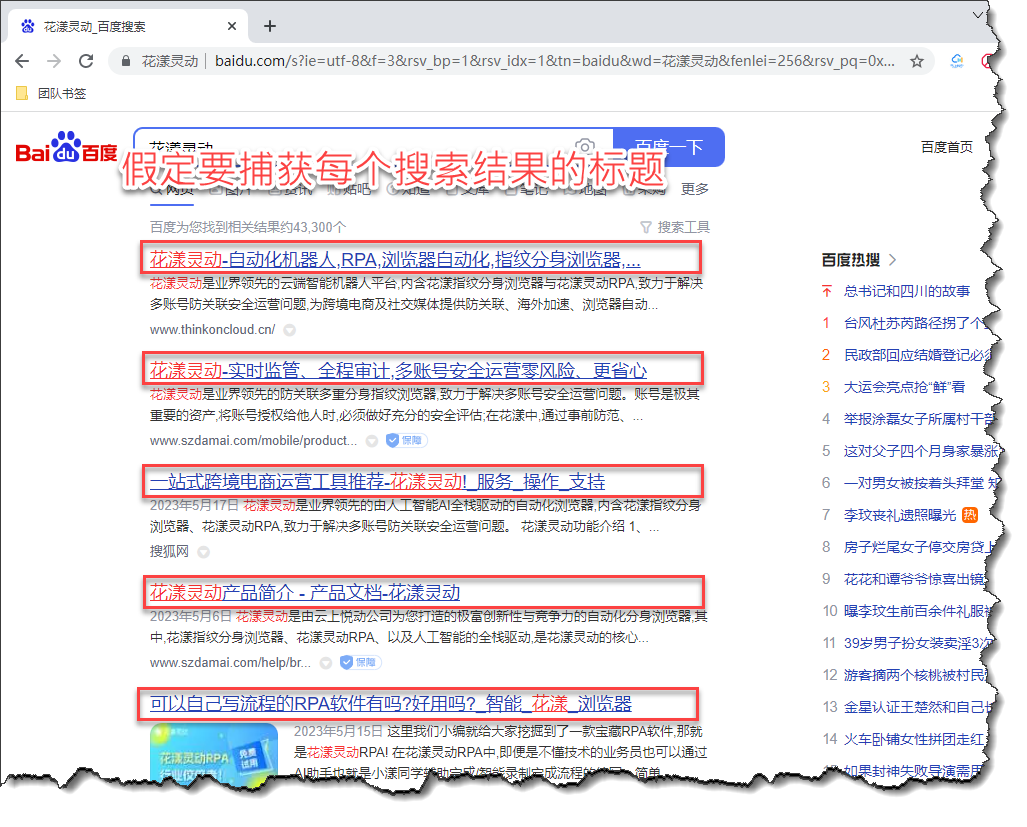
《拟捕获百度搜索结果集》
其操作步骤如下:
- 先捕获第1个搜索结果的标题
- 点击“捕获相似元素”,然后捕获第2个搜索结果的标题
- 元素捕获器会自动根据两个元素的共性,帮助我们寻找所有相似的元素
为方便您的理解,请参考下述GIF动画:
《网页元素捕获器》
7、网页元素捕获器的高级用法
7.1 元素预览
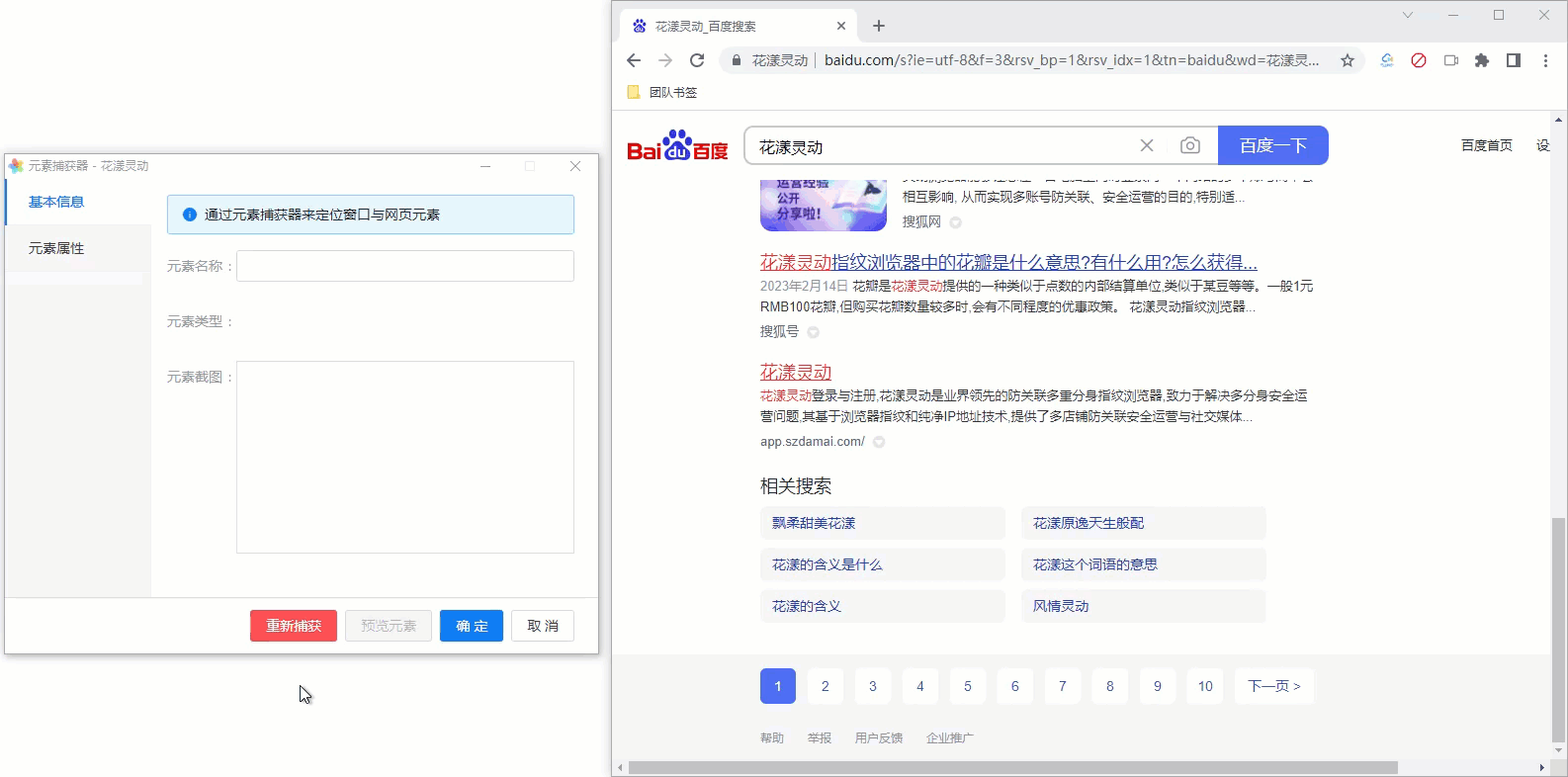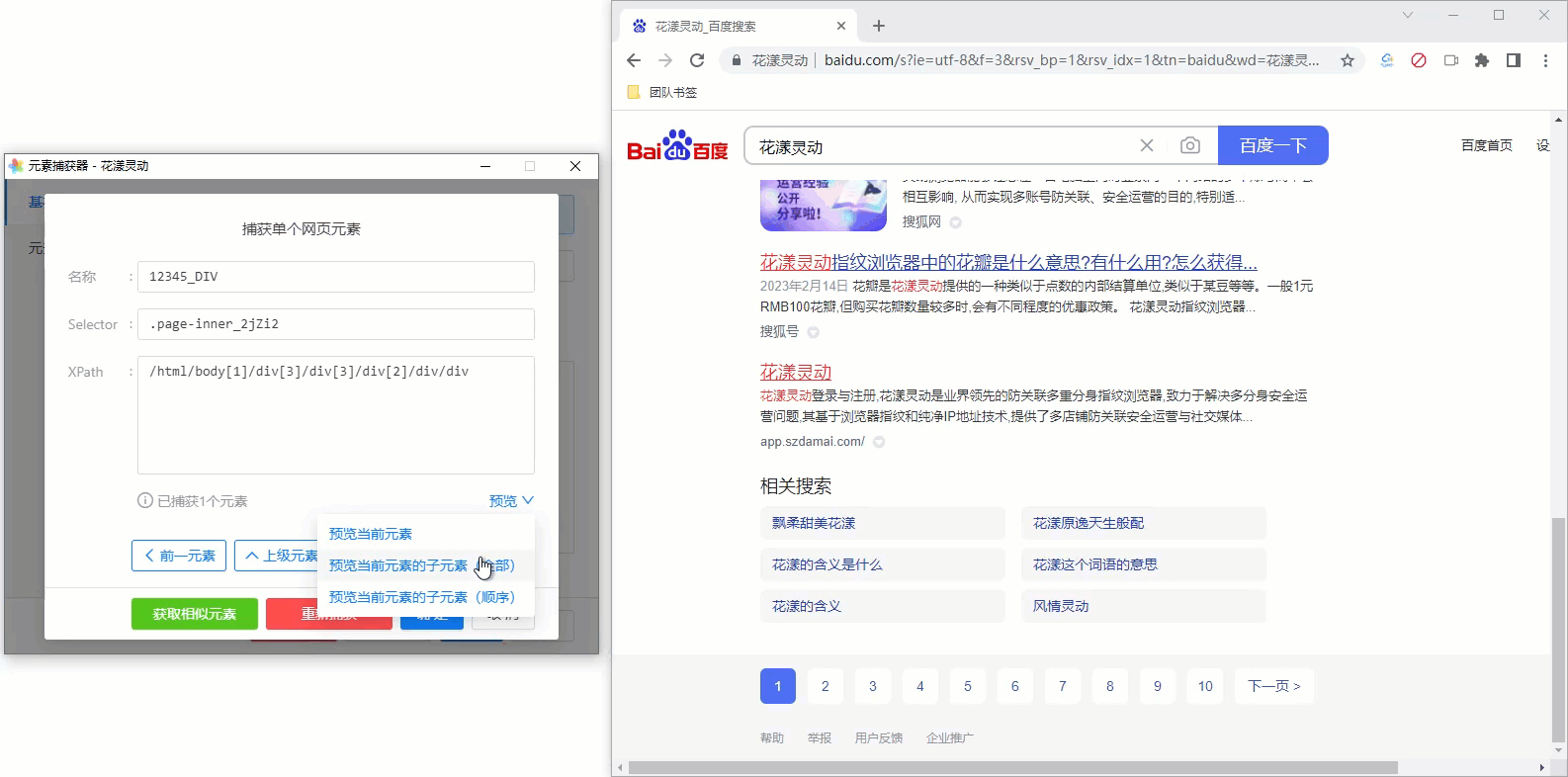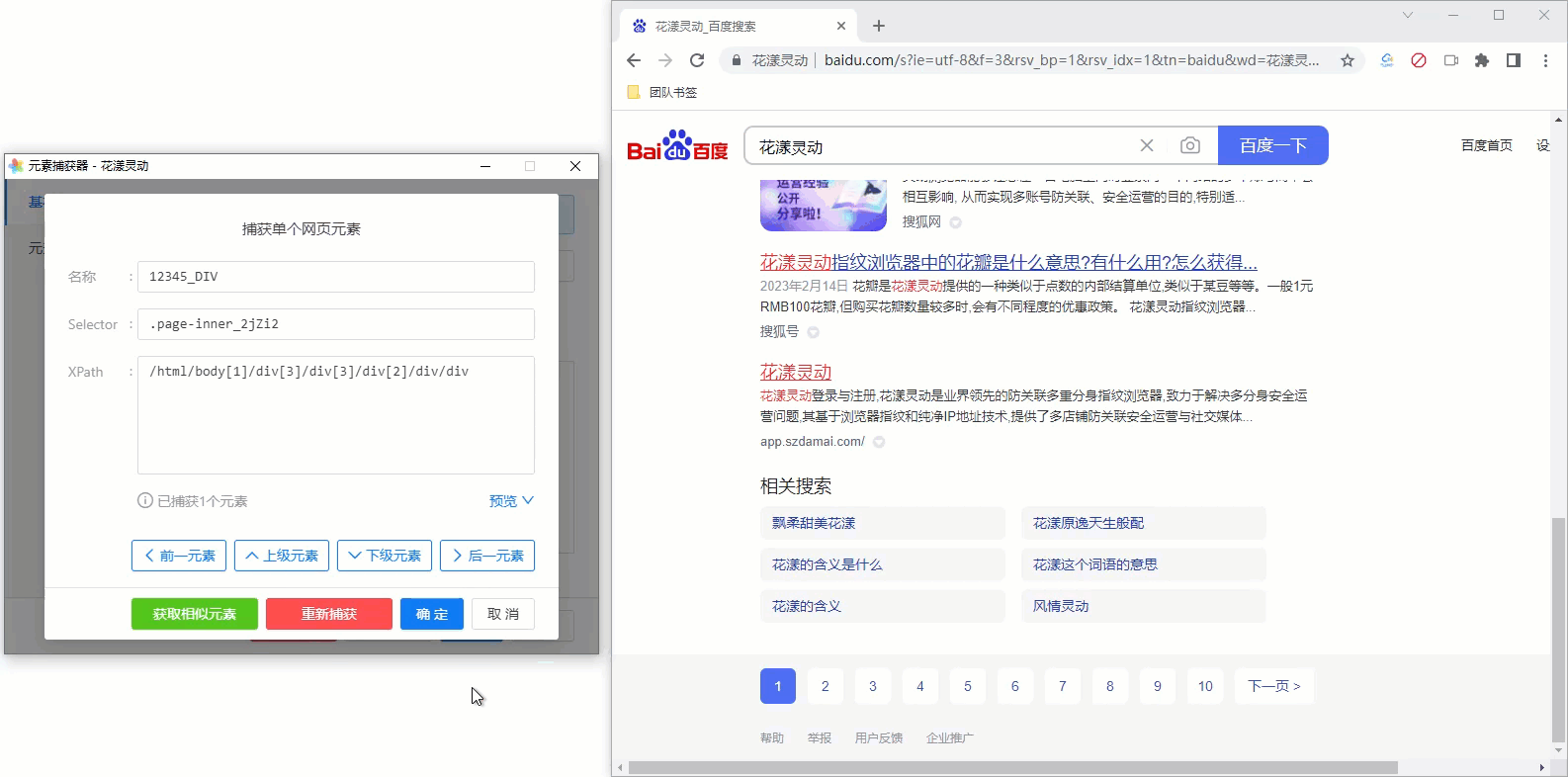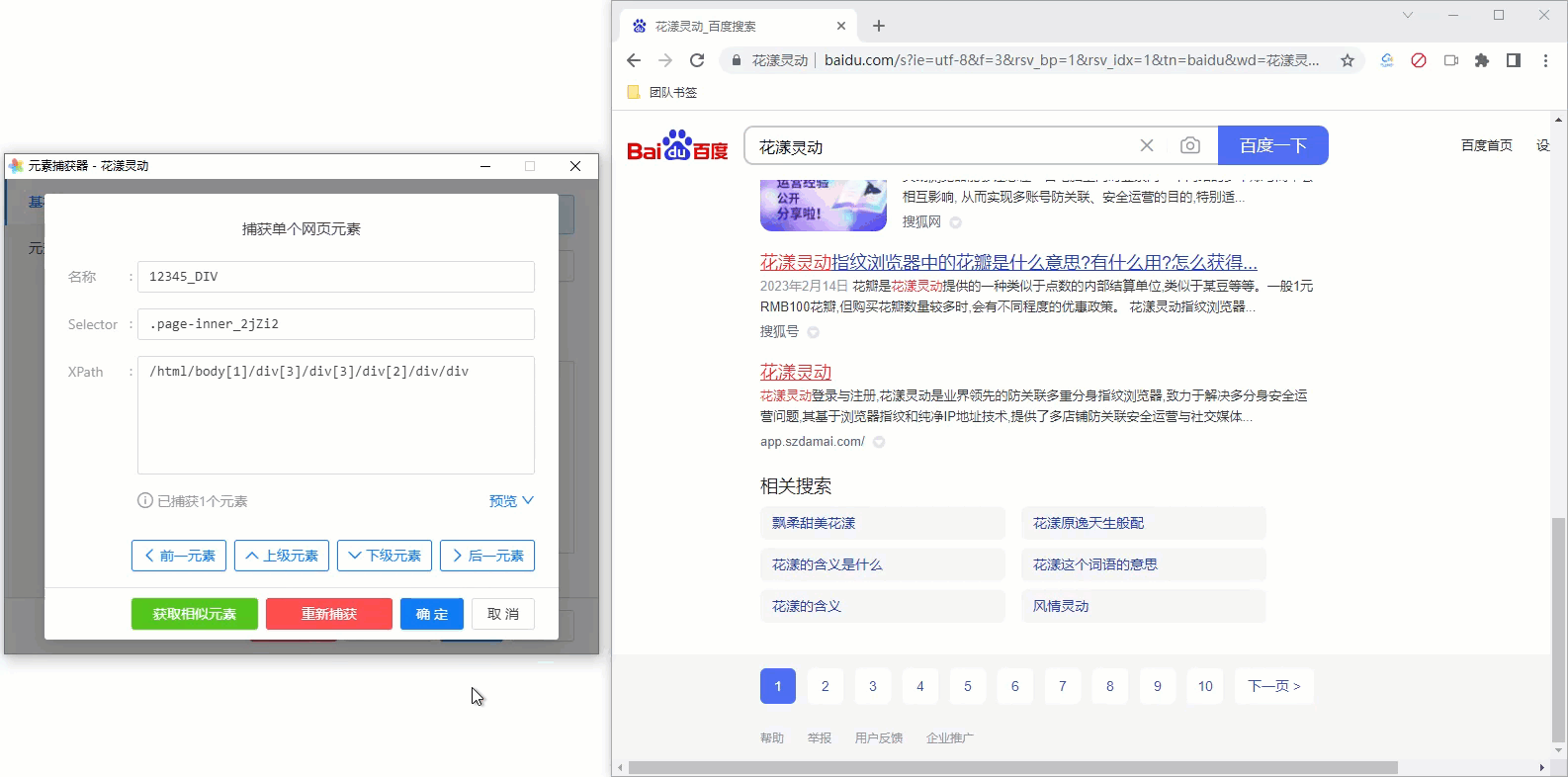
可以通过网页元素捕获器的预览功能,方便您判断当前捕获的元素是否符合您的要求。我们以百度搜索的导航条为例:
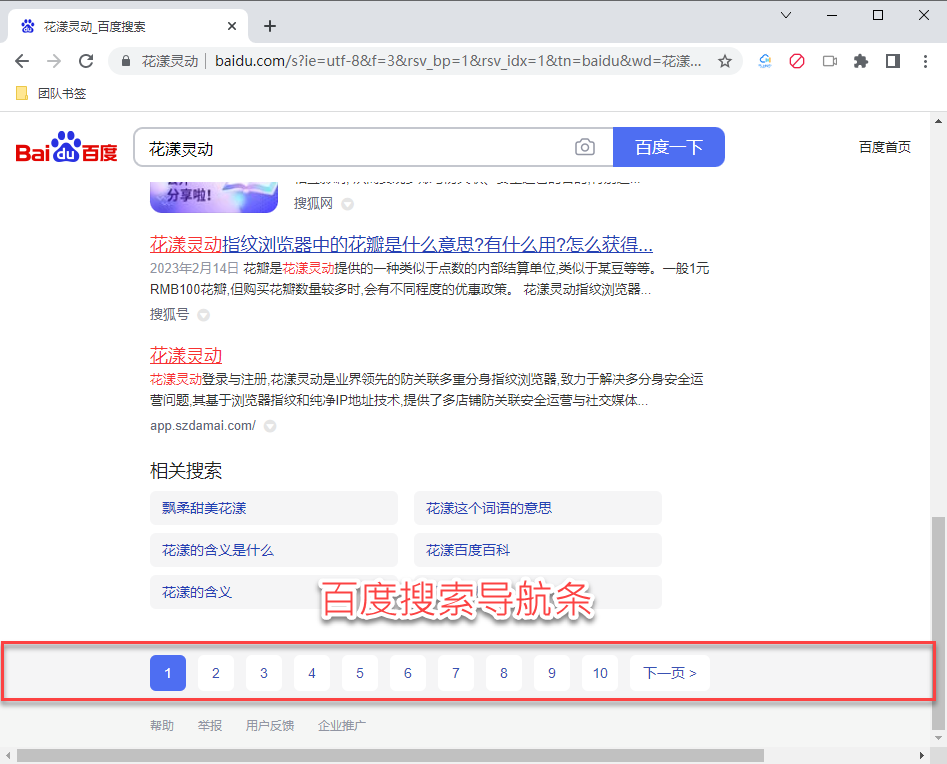
《百度搜索导航条》
假定我们现在捕获了百度搜索的导航条,为了校验我们的捕获是否正确,可以:
- 预览当前元素:以高亮形式显示当前捕获的元素
- 预览当前元素的子元素(全部):以高亮形式、全部同时显示当前捕获元素的子元素
- 预览当前元素的子元素(顺序):以高亮形式、依次顺序显示当前捕获元素的子元素
为方便您的理解,请参考下述GIF动画:
《网页元素的预览》
7.2 元素导航
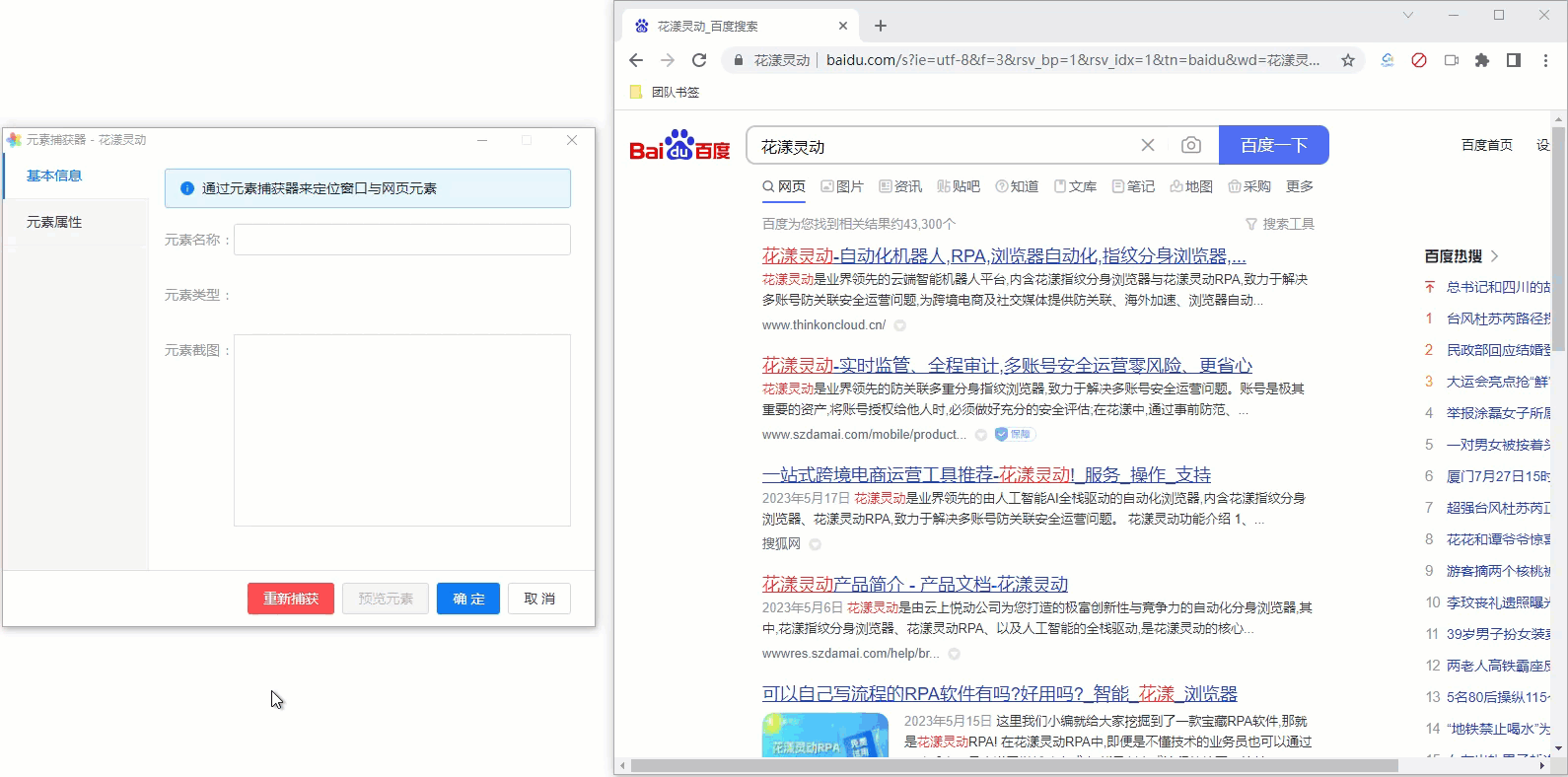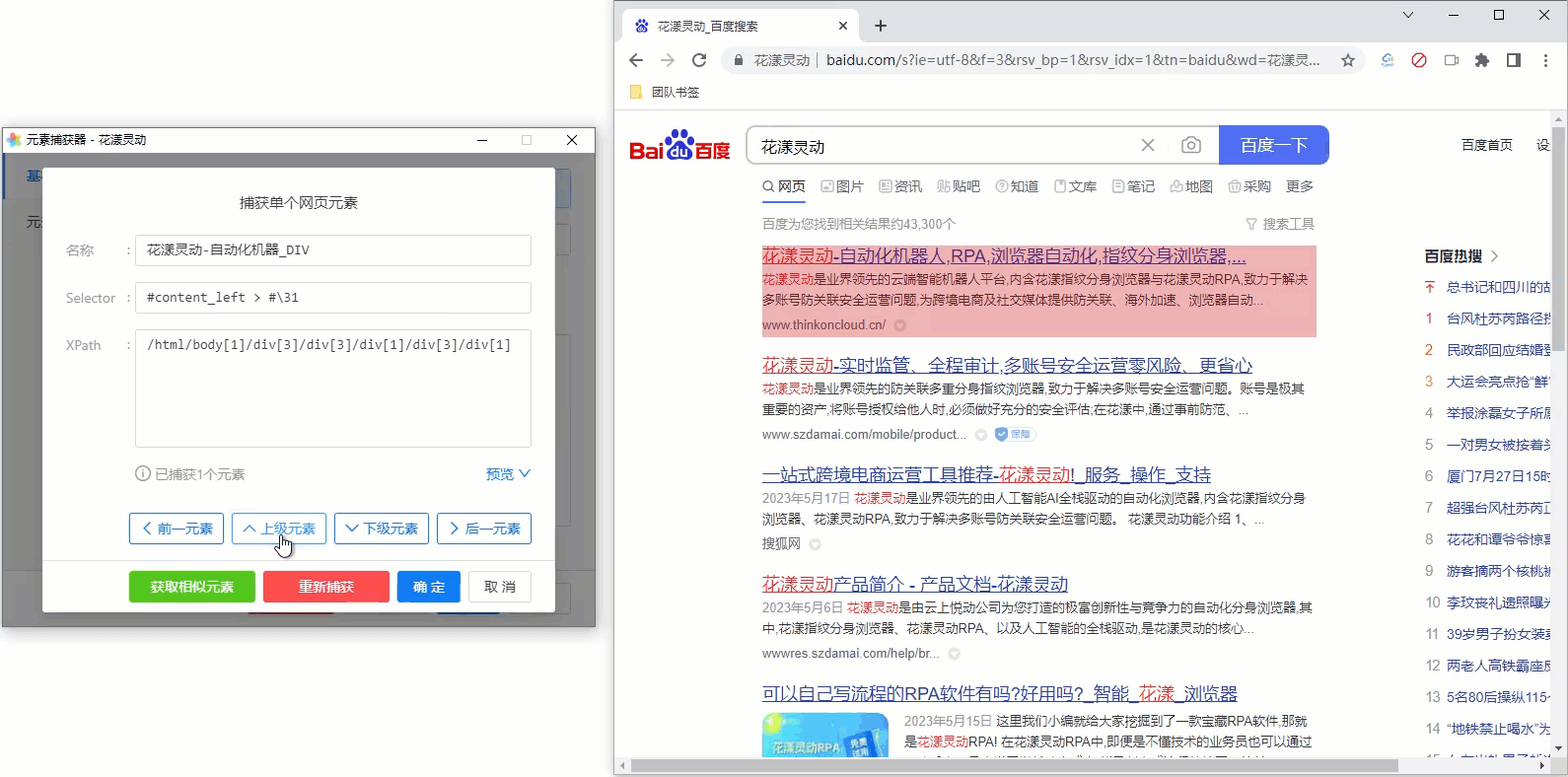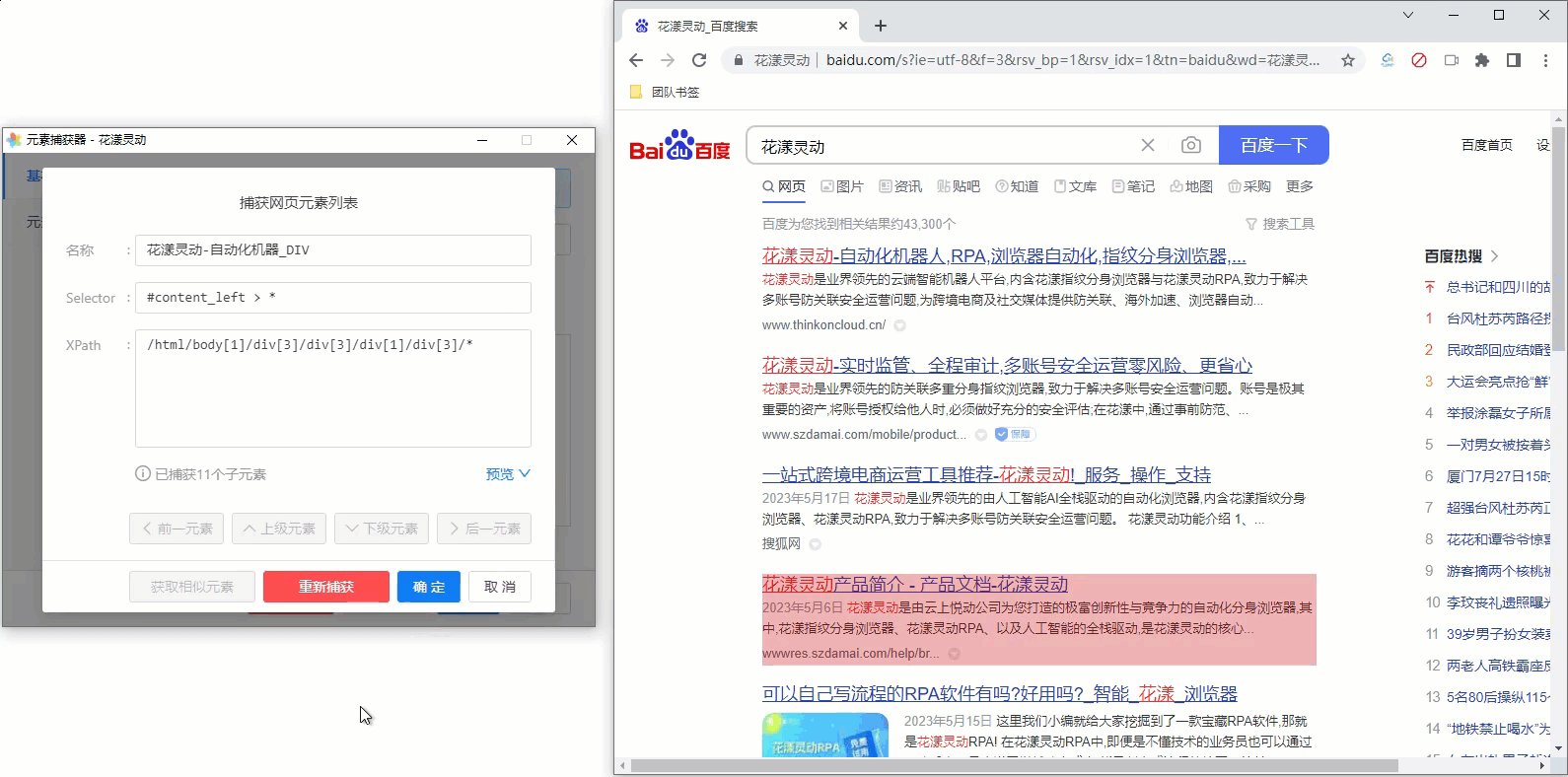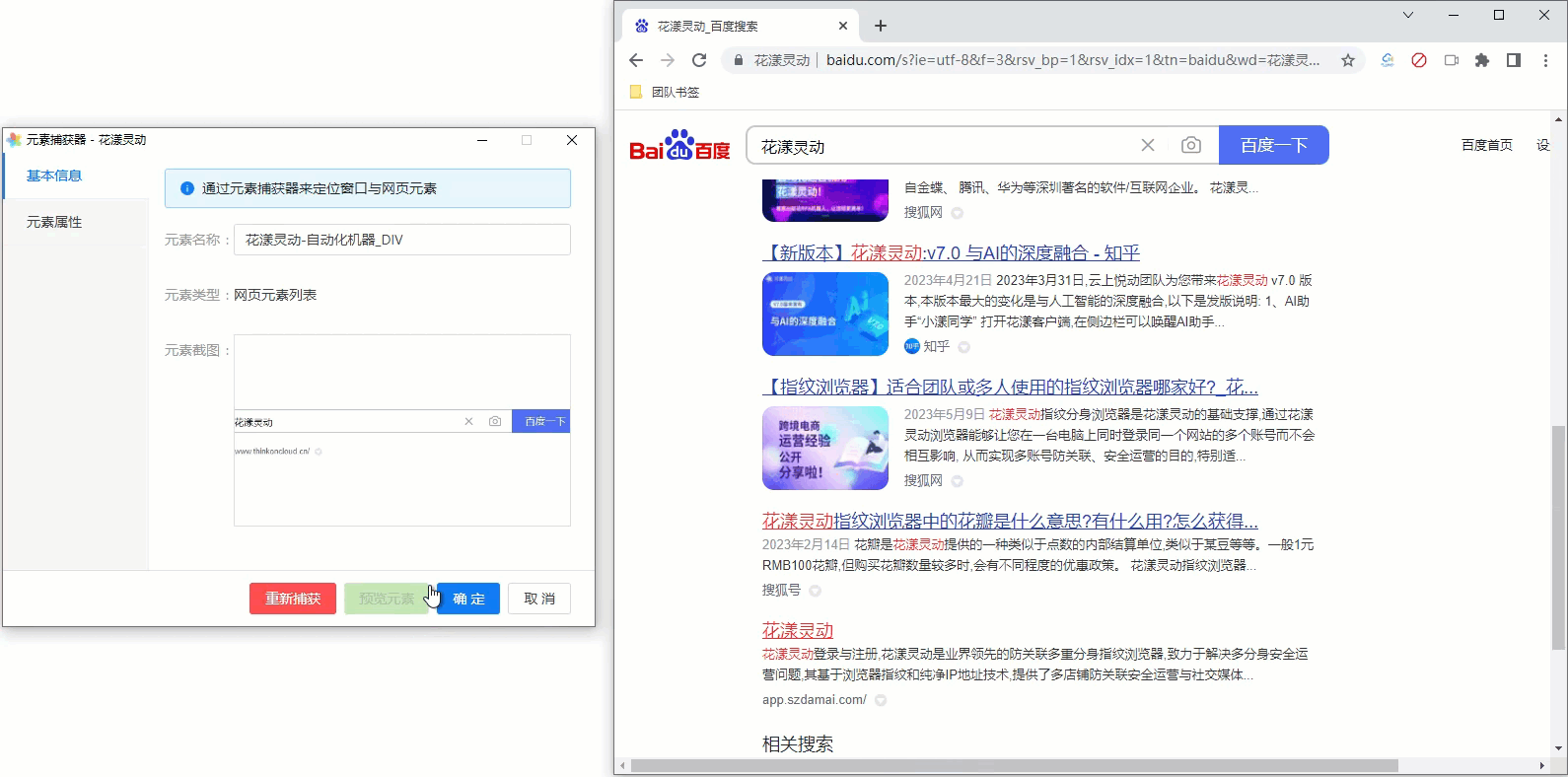
考虑到网页元素各种千奇百怪的形态,有时我们无法一次定位到正确的网页元素,此时可以先捕获一个相近的元素,然后通过“元素导航”按钮, 间接定位到目标值。我们还是以百度搜索为例,假定现在要捕获每个搜索结果,这是一个类似于 DIV 的容器元素, 如下图所示:
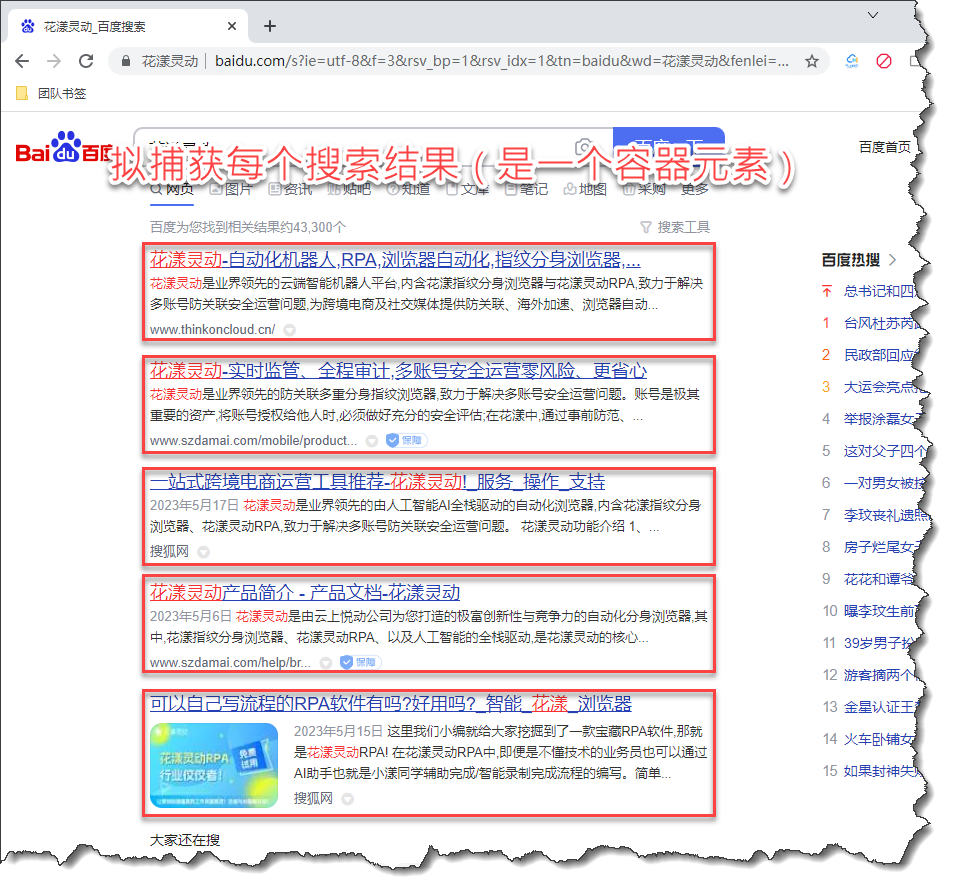
《捕获百度搜索结果容器元素》
由于我们无法一次定位到该容器元素,一个比较聪明的做法是,先找到一个搜索结果,然后通过元素捕获器中的“上级元素”、“下级元素”等导航按钮, 逐步定位到我们的目标值;期间随时通过预览功能,检查是否捕获到了我们期望的目标元素。 为方便您的理解,请参考下述GIF动画:
《网页元素的导航》
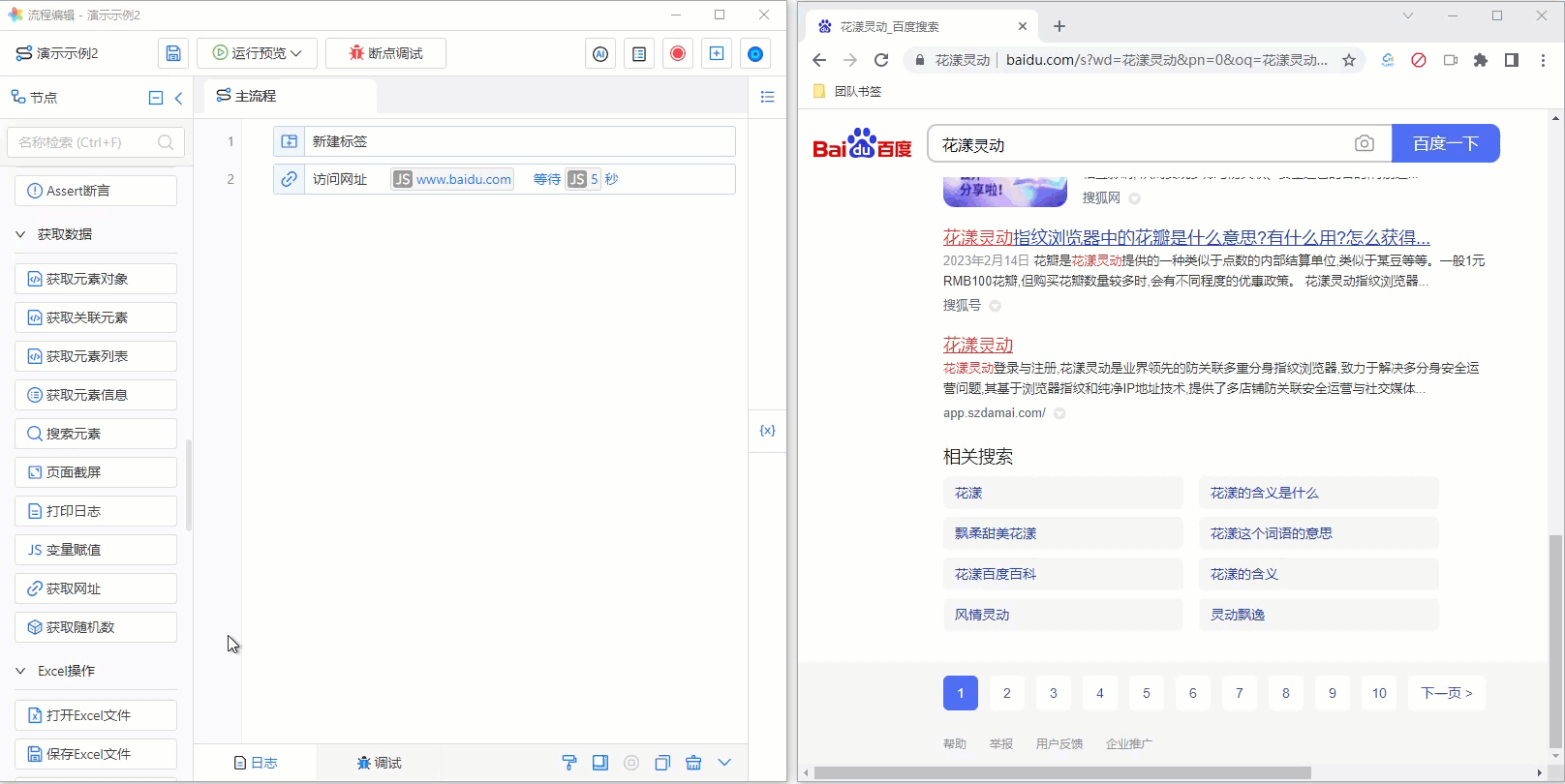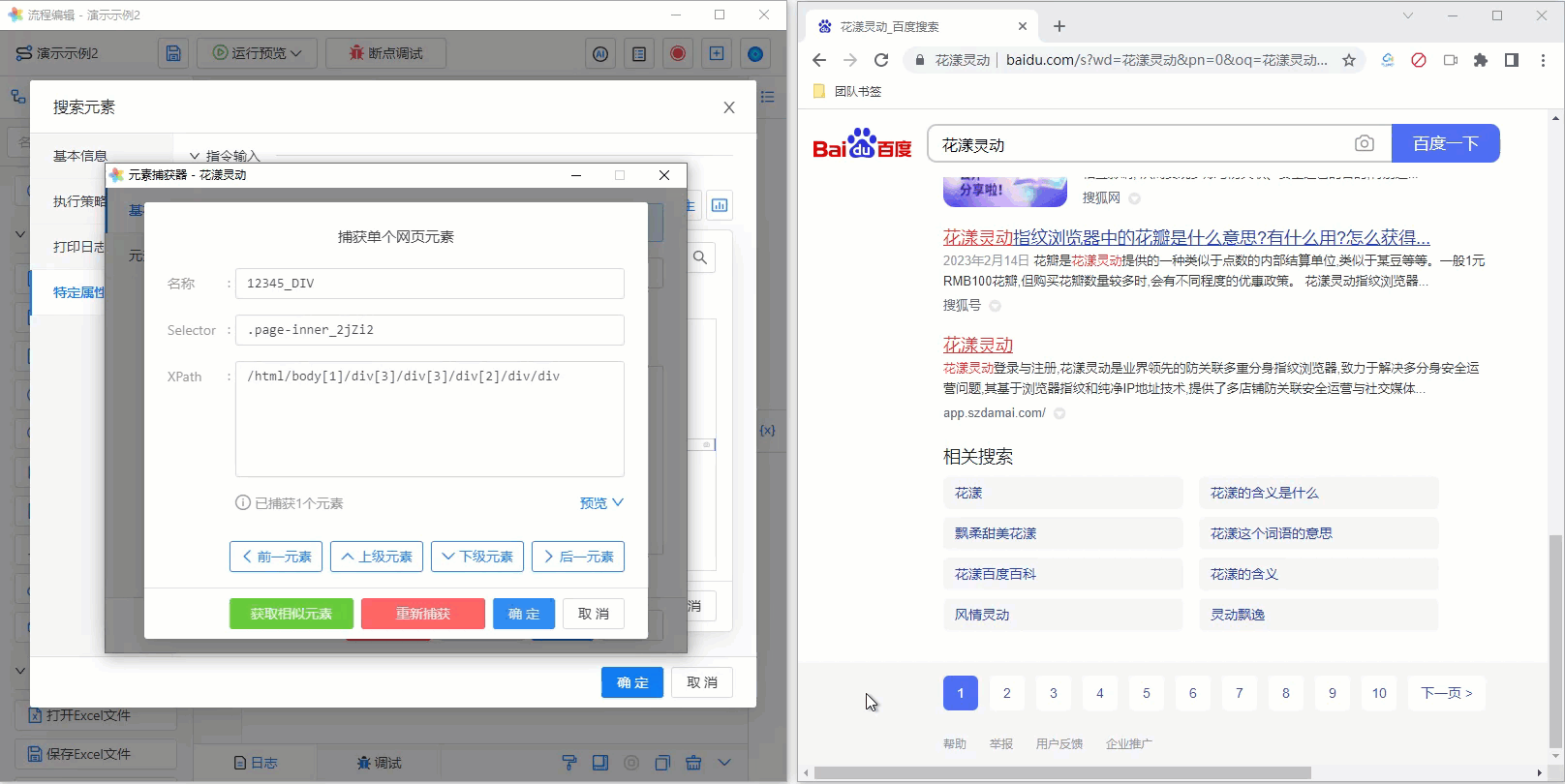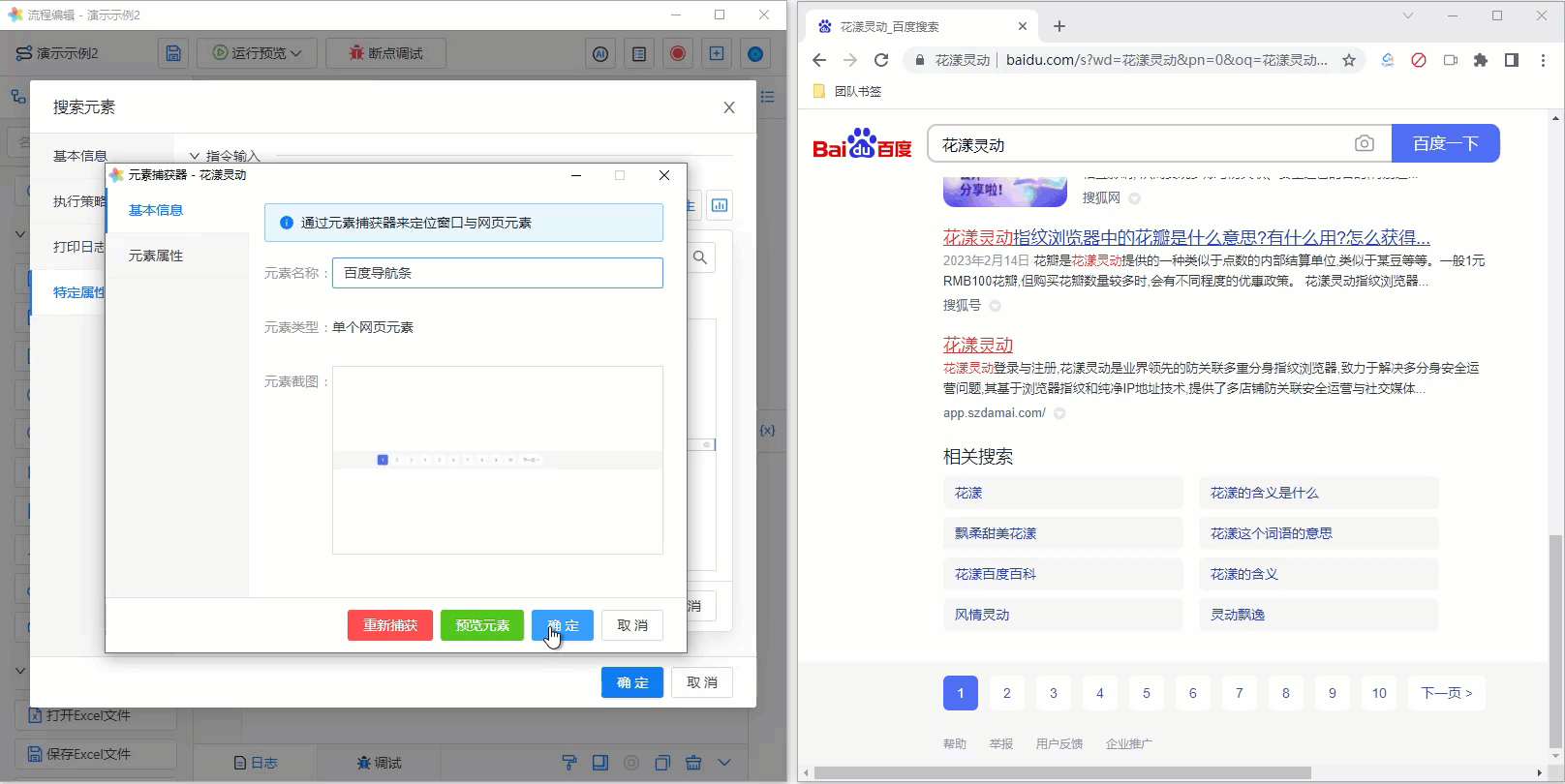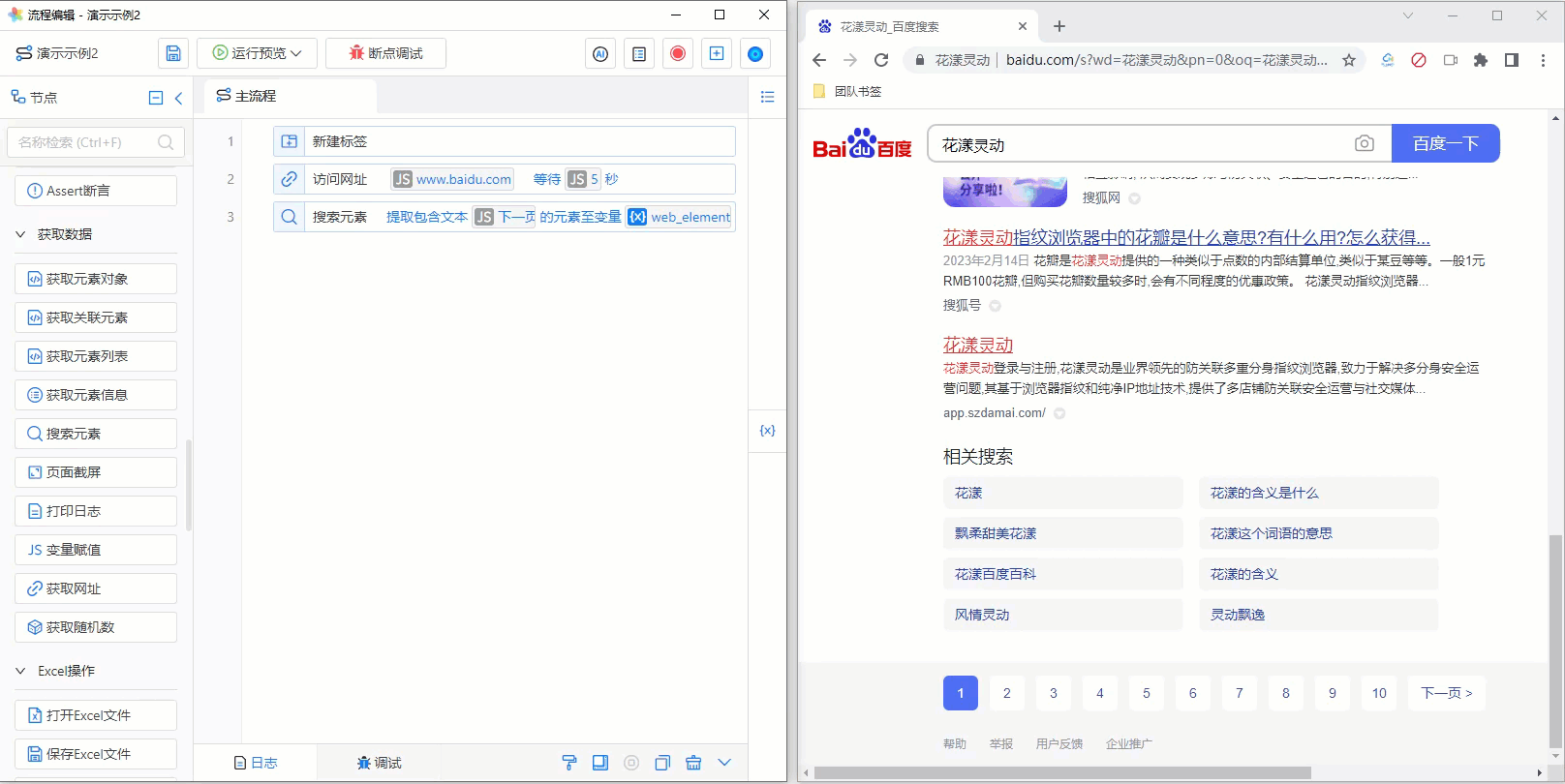
8、搜索元素
有时候我们眼中所看到的同一个网页元素,事实上拥有不同的定位符。以百度搜索结果的导航条为例,每个页面都有“下一页”这个按钮, 但事实上,如果我们用元素捕获器来捕获这个网页元素,可以发觉:在第1页中的“下一页”,和第2页或者第3页中的“下一页”, 拥有完全不同的Selector与XPath,换言之,如果通过常规的Selector与XPath等手段,无法准确的定位此元素。
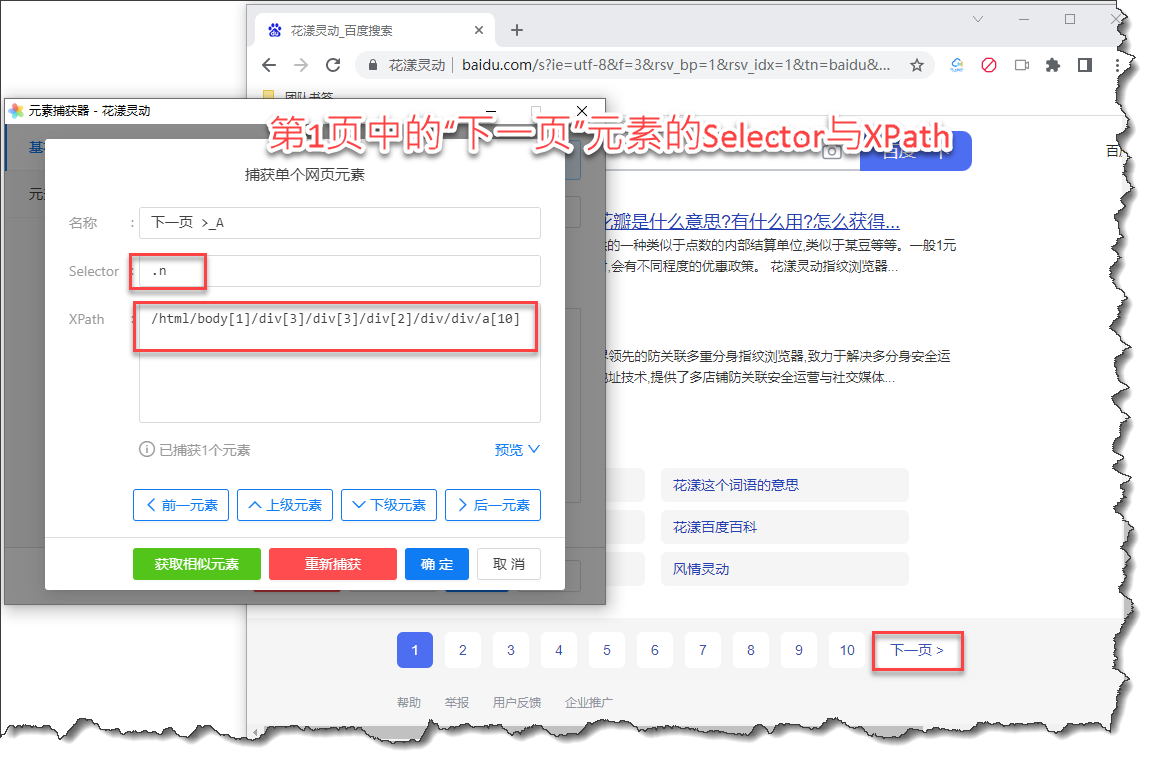
《在第1页中百度导航条中的“下一页”网页元素》
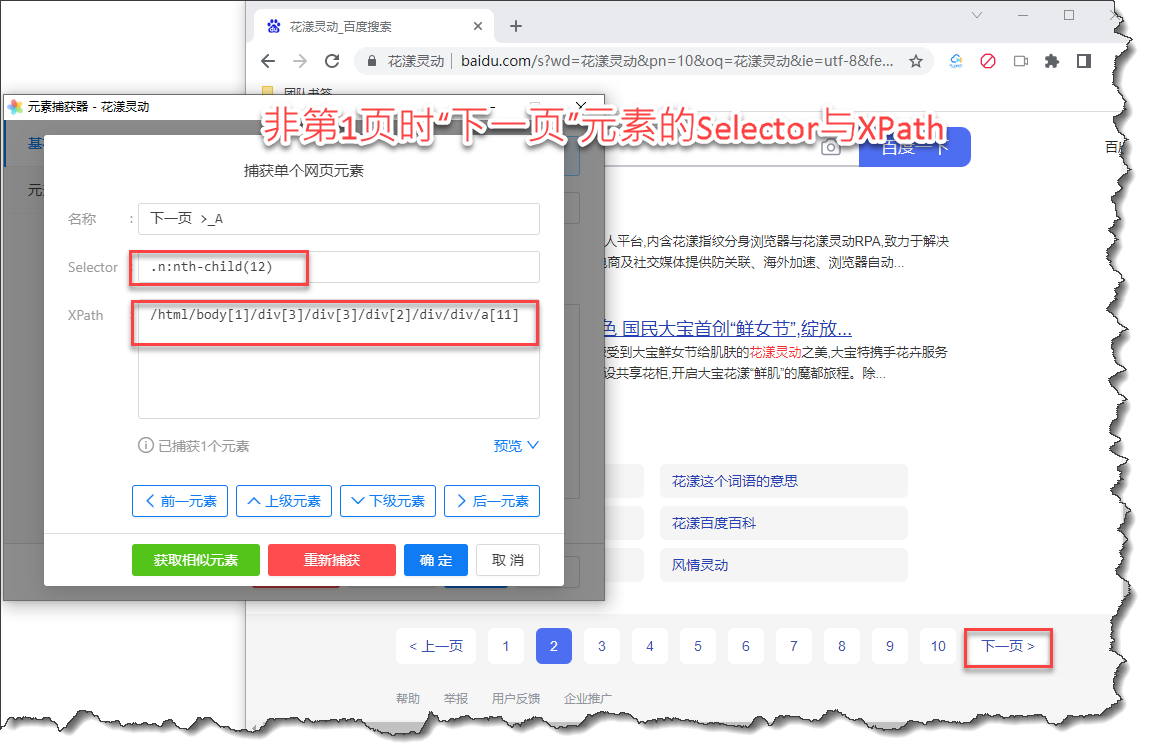
《在第2页中百度导航条中的“下一页”网页元素》
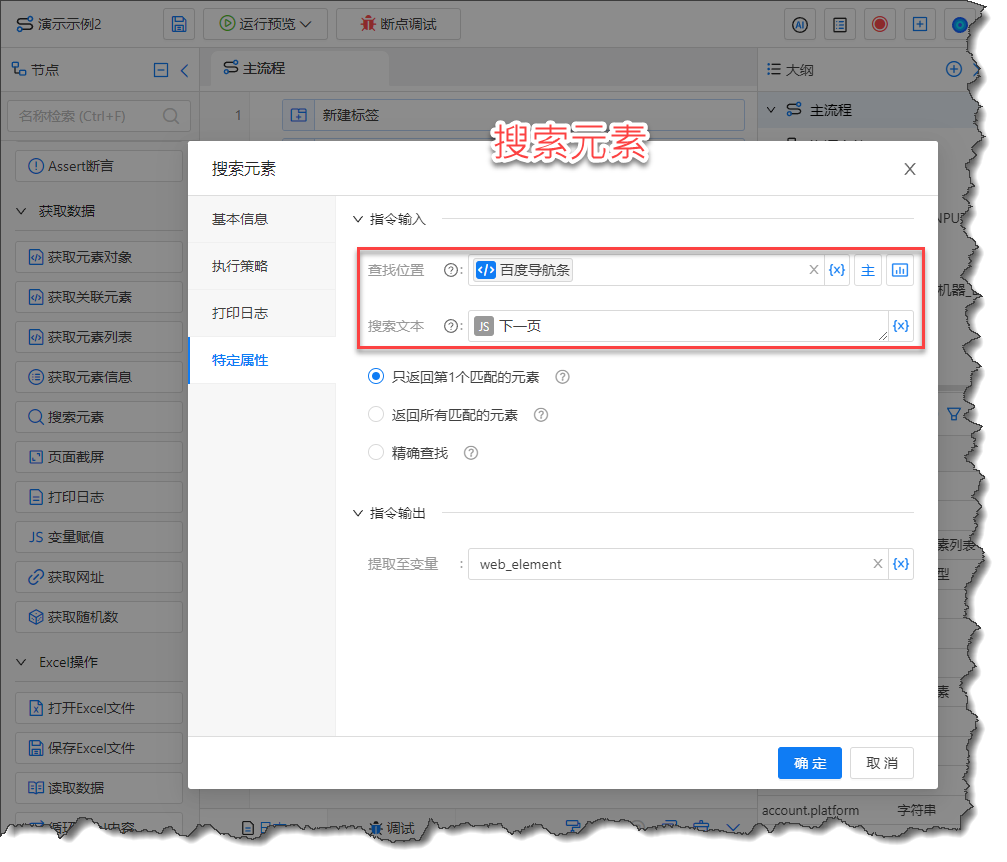
在这种情况下,我们推荐您使用“搜索元素”流程节点,如下图所示:
《搜索元素的使用说明》
“搜索元素”流程节点的使用说明如下:
- 查找位置:默认不填时会在整个页面(暨<body>)中查找,显然这有可能返回错误的结果或者多个结果,推荐设置精确的位置,以百度导航条为例,在该区域内只会有一个“下一页”,故通过网页元素捕获器捕获百度导航条所处位置即可
- 搜索文本:拟查找的文本
为方便您的理解,请参考下述GIF动画:
《搜索元素的使用说明》
9、总结
- 网页元素也称之为页面节点,一个网页是由若干个网页元素组成的
- 我们通过网页元素的 Selector 或 XPath 来定位网页元素的位置
- 通过花漾灵动提供的“网页元素捕获器”,能够非常方便的帮助我们捕获网页元素
- 如果通过 Selector 或 XPath 不能定位网页元素,可以通过 “搜索元素” 达成我们的目标
最后,针对本文所介绍的内容,我们为您准备了以下视频教程,辅助您了解相关内容:

